Extended Reality and Perception
Virtual Reality provides a new way of experiencing virtual content with unprecedented capabilities that have the potential of profoundly impact our society. However little is known about how this new scenario influences users’ perception. Our research efforts are targeted towards understanding viewers’ behavior in immersive VR environments.
With the proliferation of low-cost, consumer level head-mounted displays (HMDs), Virtual Reality (VR) is progressively entering the consumer market. VR systems provide a new way of experiencing virtual content that is richer than radio, or television, yet also different from how we experience the real world. These unprecedented capabilities for creating new content have the potential to profoundly impact our society. However, little is known about how this new scenario may affect users’ behavior, especially in narrative VR: How does one design or edit 3D scenes effectively in order to retain or guide users’ attention? Can we predict users’ behavior and react accordingly? How does one create a satisfactory cinematic VR cinematic experience? On a more fundamental level, our understanding of how to tell stories may have to be revised for VR. To derive conventions for storytelling from first principles, it is crucial to understand how users explore virtual environments and what constitutes attention. Such an understanding would also inform future designs of user interfaces, eye tracking technology, and other key aspects of VR systems.
Funding agencies

Publications
Overdriving Visual Depth Perception via Sound Modulation in VR
Daniel Jimenez Navarro, Colin Groth, Xi Peng, Jorge Pina, Qi Sun, Praneeth Chakravarthula, Karol Myszkowski, Hans-Peter Seidel, Ana Serrano
IEEE Transactions on Visualization and Computer Graphics (IEEE VR 2026)

Abstract: Our ability to perceive and navigate the spatial world is a cornerstone of human experience, relying on the integration of visual and auditory cues to form a coherent sense of depth and distance. In stereoscopic 3D vision, depth perception requires fixation of both eyes on a target object, which is achieved through vergence movements, with convergence for near objects and divergence for distant ones. In contrast, auditory cues provide complementary depth information through variations in loudness, interaural differences (IAD), and the frequency spectrum. We investigate the interaction between visual and auditory cues and examine how contradictory auditory information can overdrive visual depth perception in virtual reality (VR). When a new visual target appears, we introduce a spatial discrepancy between the visual and auditory cues: the visual target is shifted closer to the previously fixated object, while the corresponding sound localization is displaced in the opposite direction. By integrating these conflicting cues through multimodal processing, the resulting percept is biased toward the intended depth location. This audiovisual fusion counteracts depth compression, thus reducing the required vergence magnitude and enabling faster gaze retargeting. Such audio-driven depth enhancement may further help mitigate the vergence-accommodation conflict (VAC) in scenarios where physical depth must be compressed. In a series of psychophysical studies, we first assess the efficiency of depth overdriving for various VR-relevant combinations of initial fixations and shifted target locations, considering different scenarios of audio displacements and their loudness and frequency parameters. Next, we quantify the resulting speedup in gaze retargeting for target shifts that can be successfully overdriven by sound manipulations. Finally, we apply our method in a naturalistic VR scenario where user interface interactions with the scene show an extended perceptual depth.
An analysis of gaze behavior under multisensory cognitive load in immersive environments
Jaime Bielsa, Jorge Pina, Ana Serrano, Daniel Martin
Computers and Graphics (Proc. CEIG 2026)
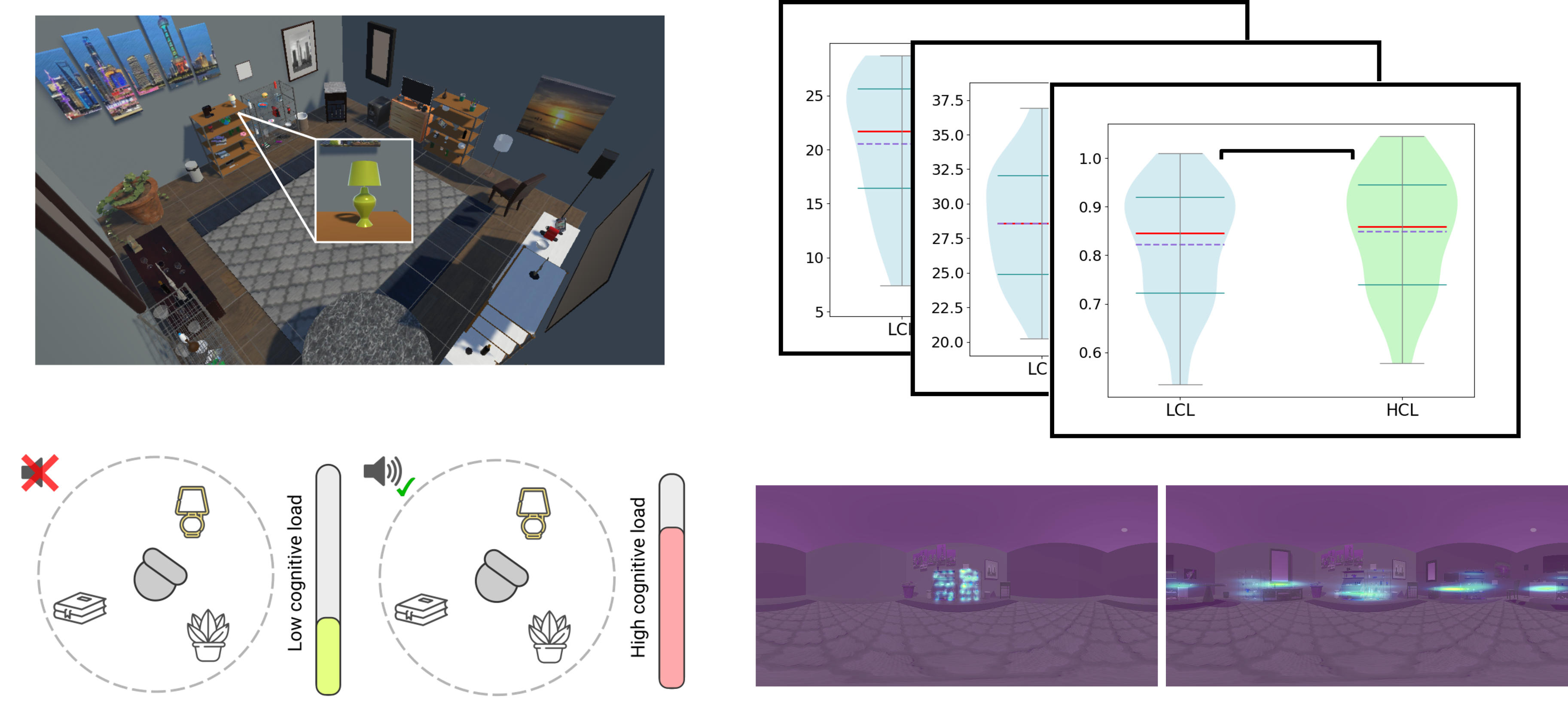
Abstract: Virtual Reality (VR) enables immersive and realistic experiences in which complex multisensory interactions often impose elevated cognitive demands on users. Excessive levels of cognitive load (CL) have been shown to degrade performance and user experience, motivating the search for robust and non-intrusive indicators for CL monitoring in immersive environments. While recent approaches have leveraged physiological signals for this purpose, many of these signals are sensitive to motion and require complex sensor setups. Given the widespread integration of eye tracking in modern head-mounted displays, gaze behavior emerges as a promising alternative for objective CL assessment. In this work, we present a comprehensive analysis of gaze behavior and its relationship to cognitive load in immersive, task-oriented VR. Using a publicly available dataset collected in a multisensory visual search experience, we first examine how a range of gaze-derived markers, including fixations, saccades, eye eccentricity, and pupil dilation, vary across cognitive load conditions. We then investigate their relationship with biomarkers derived from complementary physiological signals, including electrocardiogram (ECG), electrodermal activity (EDA), and respiration, to better understand how gaze-based markers relate to broader physiological responses associated with cognitive load. Our results reveal consistent changes in oculomotor behavior under high cognitive load, characterized by reduced saccade amplitudes and eye eccentricity, together with increased pupil dilation. These patterns indicate a more centered and less exploratory visual behavior, consistent with attention tunneling under high task demands. In addition, we identify strong correlations between several gaze markers and the phasic component of electrodermal activity, a well-known indicator of mental effort. Together, these findings highlight the potential of gaze-based measures as lightweight and non-intrusive indicators of cognitive load, supporting the development of adaptive, user-aware VR applications.
Design and evaluation of a continuous interface for real-time self-reporting of VR sickness
Maria Plaza, Carmen Real, Ana Serrano, Diego Gutierrez
SIGCHI 2026 - Posters

Abstract: Precise measurements of sickness symptoms induced during a virtual reality (VR) experience are essential for evaluating VR systems and developing designs oriented toward usability, safety and user acceptance. However, VR sickness assessment typically relies either on discrete self-report questionnaires (which lack temporal resolution, interrupt the experience, thus reducing immersion, and provide coarse snapshots of symptom evolution) or on objective signals obtained with biosensors, which typically require extensive post-processing and interpretation. To address these shortcomings, we propose a continuous interface for real-time self-reporting of VR sickness, designed following a human-centered methodology. We design and evaluate three interface prototypes that allow users to report symptom intensity while remaining fully immersed in the virtual scene. Our findings demonstrate that users significantly prefer the continuous nature of our interfaces over the discrete Likert Scales of traditional questionnaires, identifying them as a more intuitive and less cognitively demanding alternative. In addition, the study allows us to identify the most suitable design according to user-centered criteria. Our contribution is an empirically evaluated continuous interface for real-time VR sickness assessment.
Exploring Gaze Behavior in Immersive VR under Cognitive Load
Jaime Bielsa, Jorge Pina, Ana Serrano, Daniel Martin
IEEE VR 2026 - Posters
Abstract: Understanding human visual attention is a cornerstone for creating engaging experiences. This task remains far from trivial, especially within immersive environments where users perform multiple multisensory tasks under varying levels of cognitive load. In this work, we analyze gaze data from users performing a multisensory visual search experiment in VR, focusing on the differences in visual behavior across various cognitive load levels and search areas. Results suggest a gaze stabilization strategy translated into significantly smaller saccades and eye eccentricity, which may relate to sensorimotor economy.
PreciseCam: Precise Camera Control for Text-to-Image Generation
Edurne Bernal-Berdun, Ana Serrano, Belen Masia, Matheus Gadelha, Yannick Hold-Geoffroy, Xin Sun, Diego Gutierrez
The IEEE / CVF Computer Vision and Pattern Recognition Conference (CVPR)

Abstract: Images as an artistic medium often rely on specific camera angles and lens distortions to convey ideas or emotions; however, such precise control is missing in current text-to-image models. We propose an efficient and general solution that allows precise control over the camera when generating both photographic and artistic images. Unlike prior methods that rely on predefined shots, we rely solely on four simple extrinsic and intrinsic camera parameters, removing the need for pre-existing geometry, reference 3D objects, and multi-view data. We also present a novel dataset with more than 57,000 images, along with their text prompts and ground-truth camera parameters. Our evaluation shows precise camera control in text-to-image generation, surpassing traditional prompt engineering approaches.
Viewers perceive shape in pictures according to per-fixation perspective
Daniel Martin, Diego Gutierrez, Belen Masia, Stephen DiVerdi, Aaron Hertzmann
Scientific Reports (Nature publishing group)

Abstract: How viewers interpret different pictorial projections has been a longstanding question affecting many disciplines, including psychology, art, computer science, and vision science. The most-prominent theories assume that viewers interpret pictures according to a single linear perspective projection. Yet, no existing theory accurately describes viewers' perceptions across the wide variety of projections used throughout art history. Recently, Hertzmann hypothesized that pictorial 3D shape perception is interpreted according to a separate linear perspective for each eye fixation in a picture. We performed four experiments based on this hypothesis. The first two experiments found that viewers consider object depictions as more accurate when an object is projected according to its own local linear projection, rather than one consistent with the rest of the picture. In the third experiment, viewers exhibited change blindness to projections in peripheral vision, suggesting that perception of shape primarily occurs around fixations. The fourth experiment found surface slant compensation to be dependent on fixation. We conclude that pictorial shape perception operates according to per-fixation perspective.
Audiovisual Disparities in VR: Impact on Spatial Perception
Edurne Bernal-Berdun*, Mateo Vallejo*, Qi Sun, Ana Serrano, Diego Gutierrez
IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2025
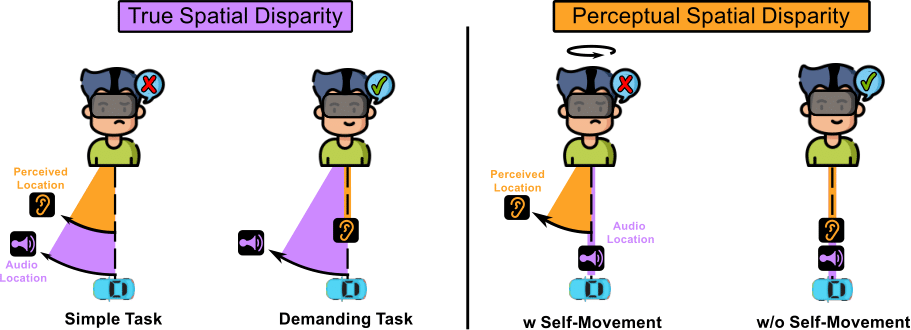
Abstract: Virtual reality (VR) experiences often leverage rich and spatialized multimodal environments to increase immersion and engagement. This demands a consistent spatial perception of audiovisual stimuli, since perceived discrepancies can disrupt the sense of presence. In this work, we investigate the consequences of two types of spatial audiovisual disparities: true disparity, where there is a measurable spatial offset between auditory and visual cues, and perceptual disparity, where users report misalignment despite cues being colocated. Unlike most previous studies that employed controlled but simplified experimental setups, our research focuses on complex, realistic VR environments, allowing us to assess the actual implications for VR content design. Our experiments indicate that users are highly sensitive to true audiovisual disparities in controlled environments, detecting even minor misalignments. However, when engaged in additional tasks within realistic settings, their ability to notice such discrepancies diminishes significantly. We also observed that previously found perceptual disparities persist in complex audiovisual environments. However, we identify self-initiated head rotations as a key factor; its absence prevents the effect entirely. We hope our findings offer practical insights for designing more immersive and perceptually coherent VR experiences.
A Comprehensive Analysis of the Influence of Cognitive Load on Physiological Signals in Virtual Reality
Jorge Pina, Edurne Bernal-Berdun, Daniel Martin, Sandra Malpica, Carmen Real, Alberto Barquero, Pablo Armañac-Julián, Jesus Lazaro, Alba Martín-Yebra, Belen Masia, Ana Serrano
IEEE International Symposium on Mixed and Augmented Reality (ISMAR), 2025
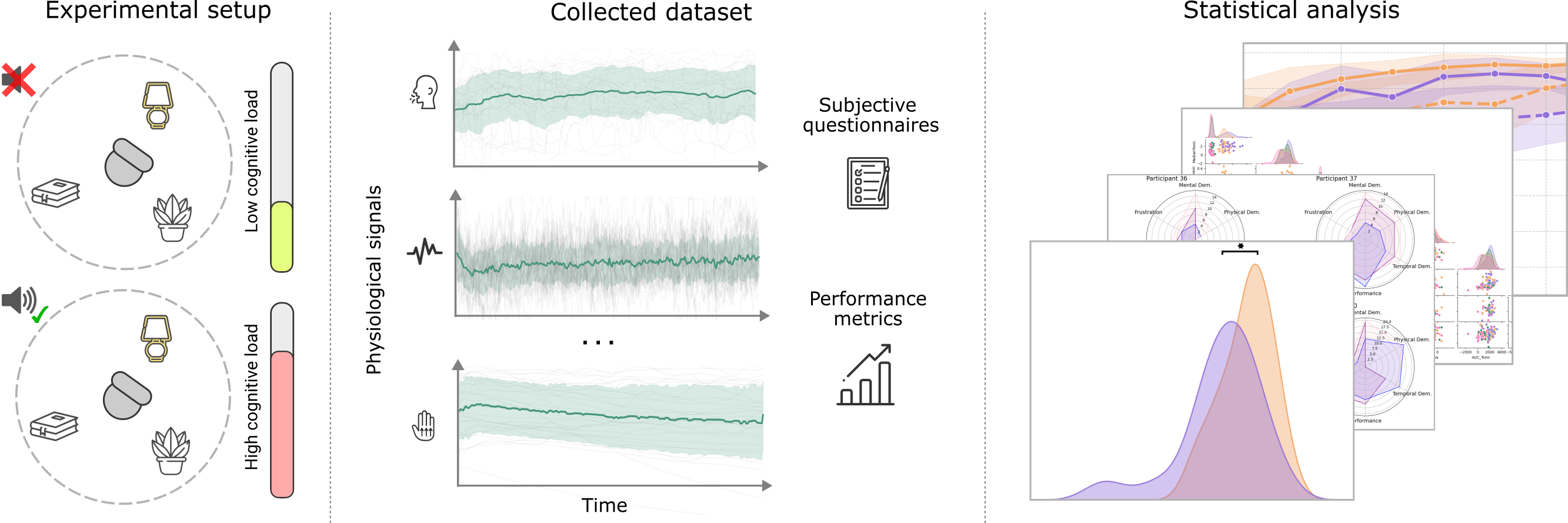
Abstract: The study of cognitive load (CL) has been an active field of research across disciplines such as psychology, education, and computer graphics and visualization for decades. In the context of Virtual Reality (VR), understanding mental demand becomes particularly relevant, as immersive experiences increasingly integrate multisensory stimuli that require users to distribute their limited cognitive resources. In this work, we investigate the effects of cognitive load during a search task in VR, combining objective and subjective measurements, including physiological signals and validated questionnaires. We designed an experiment in which participants performed a visual search task under two cognitive load conditions (either alone or while responding to a concurrent auditory task) and across two visual search areas (90° and 360°). We collected a rich dataset comprising task performance, eye tracking, electrocardiogram (ECG), electrodermal activity (EDA), photoplethysmography (PPG), and inertial measurements, along with subjective assessments (NASA-TLX questionnaires). Our analysis shows that increased cognitive load hinders visual search performance and affects multiple physiological markers, offering a solid foundation for future research on cognitive load in multisensory virtual environments.
The Effect of Cognitive Load on Visual Search Tasks in Multisensory Virtual Environments
Jorge Pina, Edurne Bernal-Berdun, Daniel Martin, Sandra Malpica, Carmen Real, Pablo Armañac-Julián, Jesus Lazaro, Alba Martín-Yebra, Belen Masia, Ana Serrano
IEEE Conference on Virtual Reality and 3D User Interfaces Poster

Abstract: Understanding cognitive load and its impact in immersive, multisensory experiences is critical for task-oriented applications like training and education. We studied the effect of cognitive load on user performance on a visual search task, performed on its own or alongside a secondary, auditory task. This effect was tested for two search areas. We were inspired by the work of Das et al. on traditional screens.
Accelerating Saccadic Response through Spatial and Temporal Cross-Modal Misalignments
Daniel Jiménez Navarro, Xi Peng, Yunxiang Zhang, Karol Myszkowski, Hans-Peter Seidel, Qi Sun, Ana Serrano
SIGGRAPH 2024
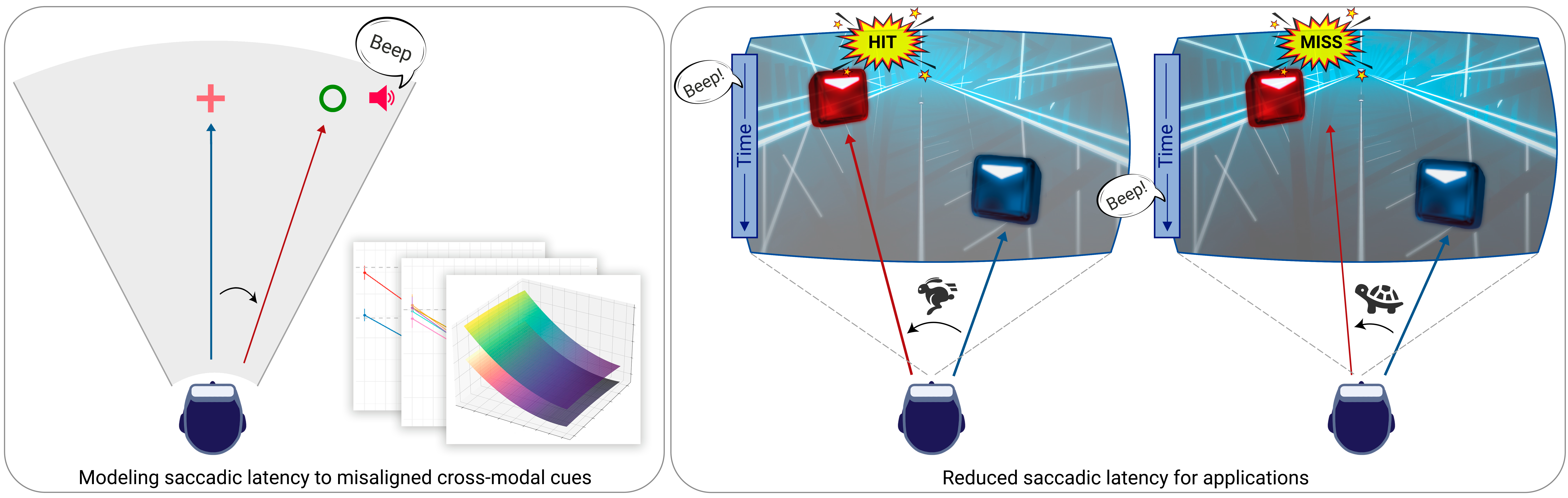
Abstract: Human senses and perception are our mechanisms to explore the external world. In this context, visual saccades --rapid and coordinated eye movements-- serve as a primary tool for awareness of our surroundings. Typically, our perception is not limited to visual stimuli alone but is enriched by cross-modal interactions, such as the combination of sight and hearing. In this work, we investigate the temporal and spatial relationship of these interactions, focusing on how auditory cues that precede visual stimuli influence saccadic latency --the time that it takes for the eyes to react and start moving towards a visual target. Our research, conducted within a virtual reality environment, reveals that auditory cues preceding visual information can significantly accelerate saccadic responses, but this effect plateaus beyond certain temporal thresholds. Additionally, while the spatial positioning of visual stimuli influences the speed of these eye movements, as reported in previous research, we find that the location of auditory cues with respect to their corresponding visual stimulus does not have a comparable effect. To validate our findings, we implement two practical applications: first, a basketball training task set in a more realistic environment with complex audiovisual signals, and second, an interactive farm game that explores previously untested values of our key factors. Lastly, we discuss various potential applications where our model could be beneficial.
Identifying Behavioral Correlates to Visual Discomfort
David Tovar, James Wilmott, Xiuyun Wu, Daniel Martin, Michael Proulx, Dave Lindberg, Yang Zhao, Olivier Mercier, Phil Guan
ACM Transactions on Graphics (Proc. SIGGRAPH Asia 2024)
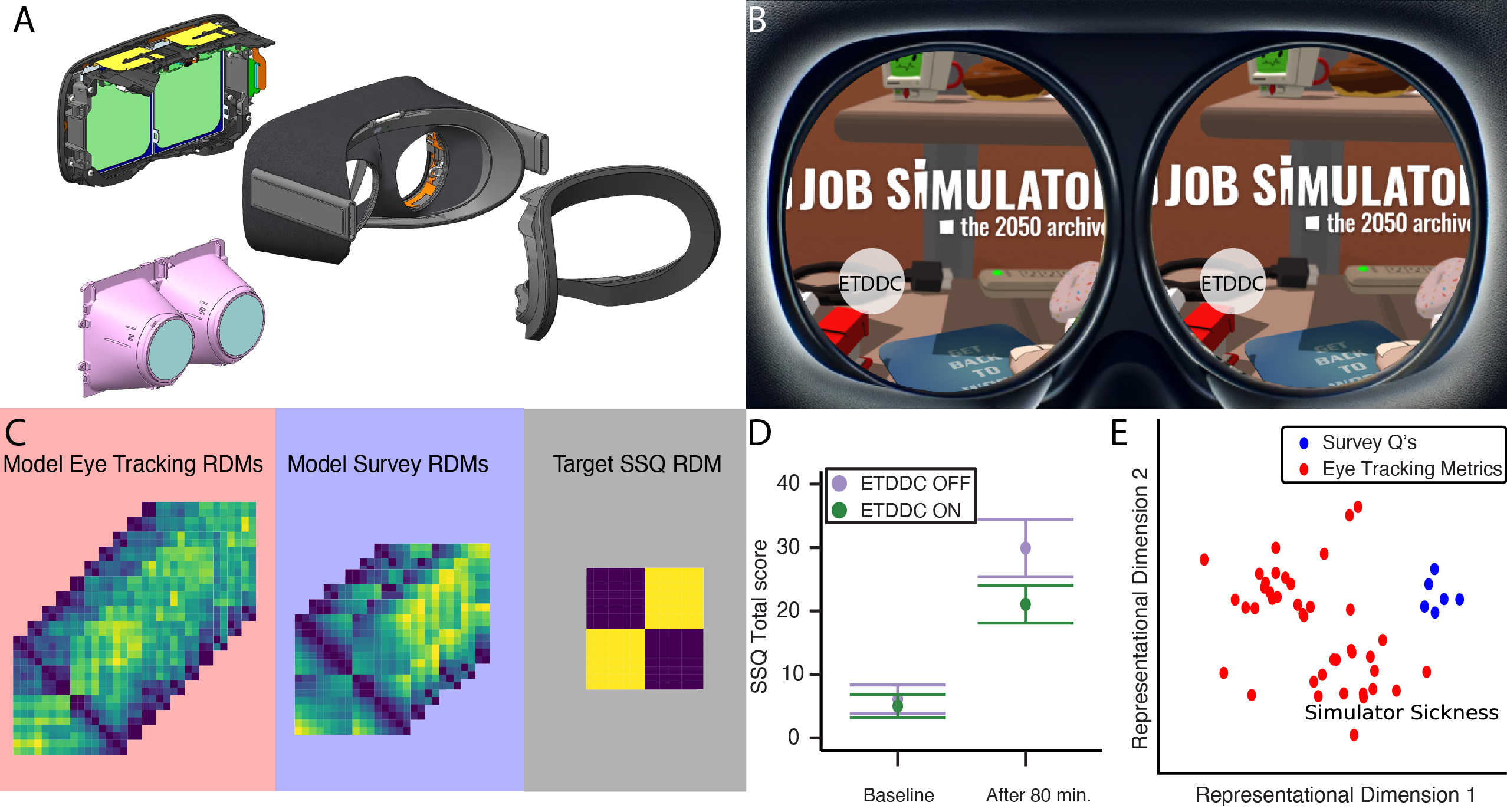
Abstract: Outside of self-report surveys, there are no proven, reliable methods to quantify visual discomfort or visually induced motion sickness symptoms when using head-mounted displays. While valuable tools, self-report surveys suffer from potential biases and low sensitivity due to variability in how respondents may assess and report their experience. Consequently, extreme visual-vestibular conflicts are generally used to induce discomfort symptoms large enough to measure reliably with surveys (e.g., stationary participants riding virtual roller coasters). An emerging area of research is the prediction of discomfort survey results from physiological and behavioral markers. However, the signals derived from experimental paradigms that are explicitly designed to be uncomfortable may not generalize to more naturalistic experiences where comfort is prioritized. In this work we introduce a custom VR headset designed to introduce significant near-eye optical distortion (i.e., pupil swim) to induce visual discomfort during more typical VR experiences. We evaluate visual comfort in our headset while users play the popular VR title Job Simulator and show that eye-tracked dynamic distortion correction improves visual comfort in a multi-session, within-subjects user study. We additionally use representational similarity analysis to highlight changes in head and gaze behavior that are potentially more sensitive to visual discomfort than surveys.
AViSal360: Audiovisual Saliency Prediction for 360º Video
Edurne Bernal-Berdun, Jorge Pina, Mateo Vallejo, Ana Serrano, Daniel Martin, Belen Masia
Proc. of ISMAR 2024

Abstract: Saliency prediction in 360◦ video plays an important role in modeling visual attention, and can be leveraged for content creation, compression techniques, or quality assessment methods, among others. Visual attention in immersive environments depends not only on visual input, but also on inputs from other sensory modalities, primarily audio. Despite this, only a minority of saliency prediction models have incorporated auditory inputs, and much remains to be explored about what auditory information is relevant and how to integrate it in the prediction. In this work, we propose an audiovisual saliency model for 360◦ video content, AViSal360. Our model integrates both spatialized and semantic audio information, together with visual inputs. We perform exhaustive comparisons to demonstrate both the actual relevance of auditory information in saliency prediction, and the superior performance of our model when compared to previous approaches.
Revisiting the Heider and Simmel experiment for social meaning attribution in virtual reality
Carlos Marañes, Ana Serrano, Diego Gutierrez
Scientific Reports (Nature Publishing Group)

Abstract: In their seminal experiment in 1944, Heider and Simmel revealed that humans have a pronounced tendency to impose narrative meaning even in the presence of simple animations of geometric shapes. Despite the shapes having no discernible features or emotions, participants attributed strong social context, meaningful interactions, and even emotions to them. This experiment, run on traditional 2D displays has since had a significant impact on fields ranging from psychology to narrative storytelling. Virtual Reality (VR), on the other hand, offers a significantly new viewing paradigm, a fundamentally different type of experience with the potential to enhance presence, engagement and immersion. In this work, we explore and analyze to what extent the findings of the original experiment by Heider and Simmel carry over into a VR setting. We replicate such experiment in both traditional 2D displays and with a head mounted display (HMD) in VR, and use both subjective (questionnaire-based) and objective (eye-tracking) metrics to record the observers’ visual behavior. We perform a thorough analysis of this data, and propose novel metrics for assessing the observers’ visual behavior. Our questionnaire-based results suggest that participants who viewed the animation through a VR headset developed stronger emotional connections with the geometric shapes than those who viewed it on a traditional 2D screen. Additionally, the analysis of our eye-tracking data indicates that participants who watched the animation in VR exhibited fewer shifts in gaze, suggesting greater engagement with the action. However, we did not find evidence of differences in how subjects perceived the roles of the shapes, with both groups interpreting the animation’s plot at the same level of accuracy. Our findings may have important implications for future psychological research using VR, especially regarding our understanding of social cognition and emotions.
Measuring and Predicting Multisensory Reaction Latency: A Probabilistic Model for Visual-Auditory Integration
Xi Peng, Yunxiang Zhang, Daniel Jiménez-Navarro, Ana Serrano, Karol Myszkowski, Qi Sun
Proc. of ISMAR 2024
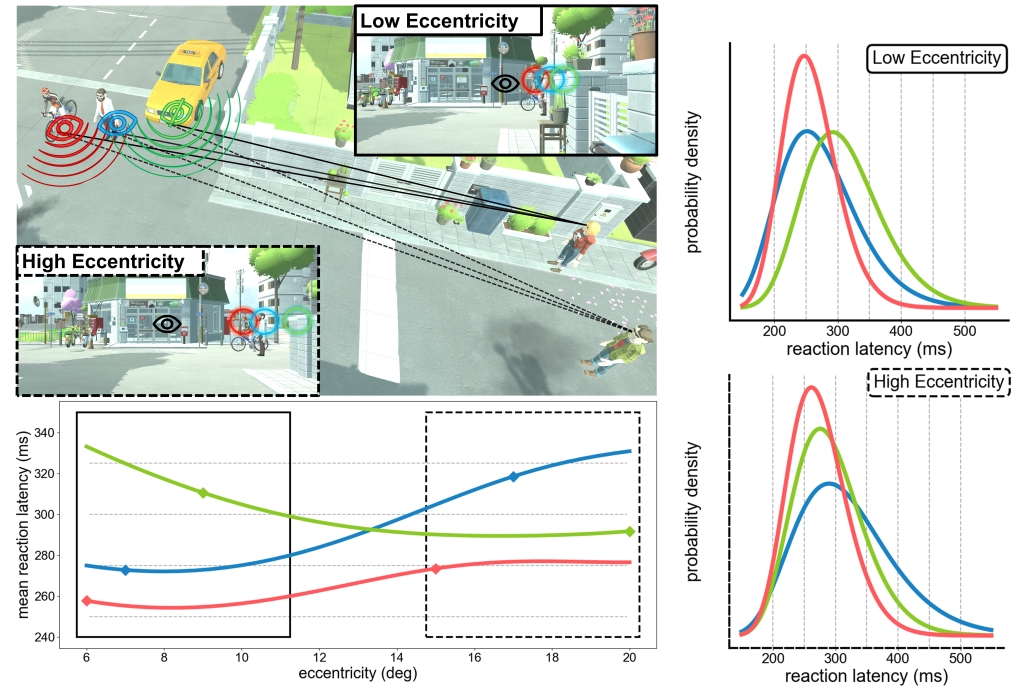
Abstract: Virtual/augmented reality (VR/AR) devices offer both immersive imagery and sound. With those wide-field cues, we can simultaneously acquire and process visual and auditory signals to quickly identify objects, make decisions, and take action. While vision often takes precedence in perception, our visual sensitivity degrades in the periphery. In contrast, auditory sensitivity can exhibit an opposite trend due to the elevated interaural time difference. What occurs when these senses are simultaneously integrated, as is common in VR applications such as 360º video watching and immersive gaming? We present a computational and probabilistic model to predict VR users’ reaction latency to visual-auditory multisensory targets. To this aim, we first conducted a psychophysical experiment in VR to measure the reaction latency by tracking the onset of eye movements. Experiments with numerical metrics and user studies with naturalistic scenarios showcase the model’s accuracy and generalizability. Lastly, we discuss the potential applications, such as measuring the sufficiency of target appearance duration in immersive video playback, and suggesting the optimal spatial layouts for AR interface design.
Modeling the Impact of Head-Body Rotations on Audio-Visual Spatial Perception for Virtual Reality Applications
Edurne Bernal-Berdun, Mateo Vallejo, Qi Sun, Ana Serrano, Diego Gutierrez
IEEE Transactions on Visualization and Computer Graphics (IEEE VR 2024)
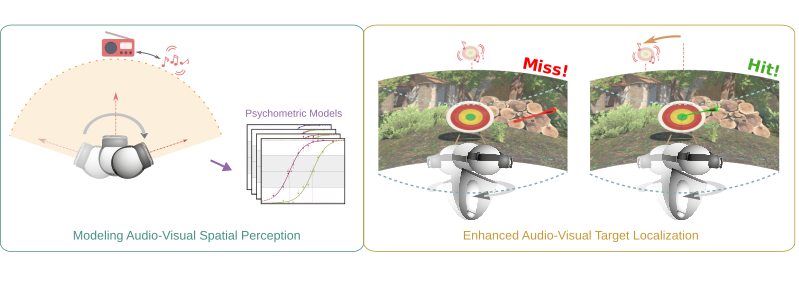
Abstract: Humans perceive the world by integrating multimodal sensory feedback, including visual and auditory stimuli, which holds true in virtual reality (VR) environments. Proper synchronization of these stimuli is crucial for perceiving a coherent and immersive VR experience. In this work, we focus on the interplay between audio and vision during localization tasks involving natural head-body rotations. We explore the impact of audio-visual offsets and rotation velocities on users' directional localization acuity for various viewing modes. Using psychometric functions, we model perceptual disparities between visual and auditory cues and determine offset detection thresholds. Our findings reveal that target localization accuracy is affected by perceptual audio-visual disparities during head-body rotations, but remains consistent in the absence of stimuli-head relative motion. We then showcase the effectiveness of our approach in predicting and enhancing users' localization accuracy within realistic VR gaming applications. To provide additional support for our findings, we implement a natural VR game wherein we apply a compensatory audio-visual offset derived from our measured psychometric functions. As a result, we demonstrate a substantial improvement of up to 40% in participants' target localization accuracy. We additionally provide guidelines for content creation to ensure coherent and seamless VR experiences.
tSPM-Net: A probabilistic spatio-temporal approach for scanpath prediction
Daniel Martin, Diego Gutierrez, Belen Masia
Computers and Graphics (Proc. CEIG 2024)

Abstract: Predicting the path followed by the viewer’s eyes when observing an image (a scanpath) is a challenging problem, particularly due to the inter- and intra-observer variability and the spatio-temporal dependencies of the visual attention process. Most existing approaches have focused on progressively optimizing the prediction of a gaze point given the previous ones. In this work we propose instead a probabilistic approach, which we call tSPM-Net. We build our method to account for observers’ variability by resorting to Bayesian deep learning and a probabilistic approach. Besides, we optimize our model to jointly consider both spatial and temporal dimensions of scanpaths using a novel spatio-temporal loss function based on a combination of Kullback–Leibler divergence and dynamic time warping. Our tSPM-Net yields results that outperform those of current state-of-the-art approaches, and are closer to the human baseline, suggesting that our model is able to generate scanpaths whose behavior closely resembles those of the real ones.
SAL3D: a model for saliency prediction in 3D meshes
Daniel Martin, Andres Fandos, Belen Masia, Ana Serrano
The Visual Computer
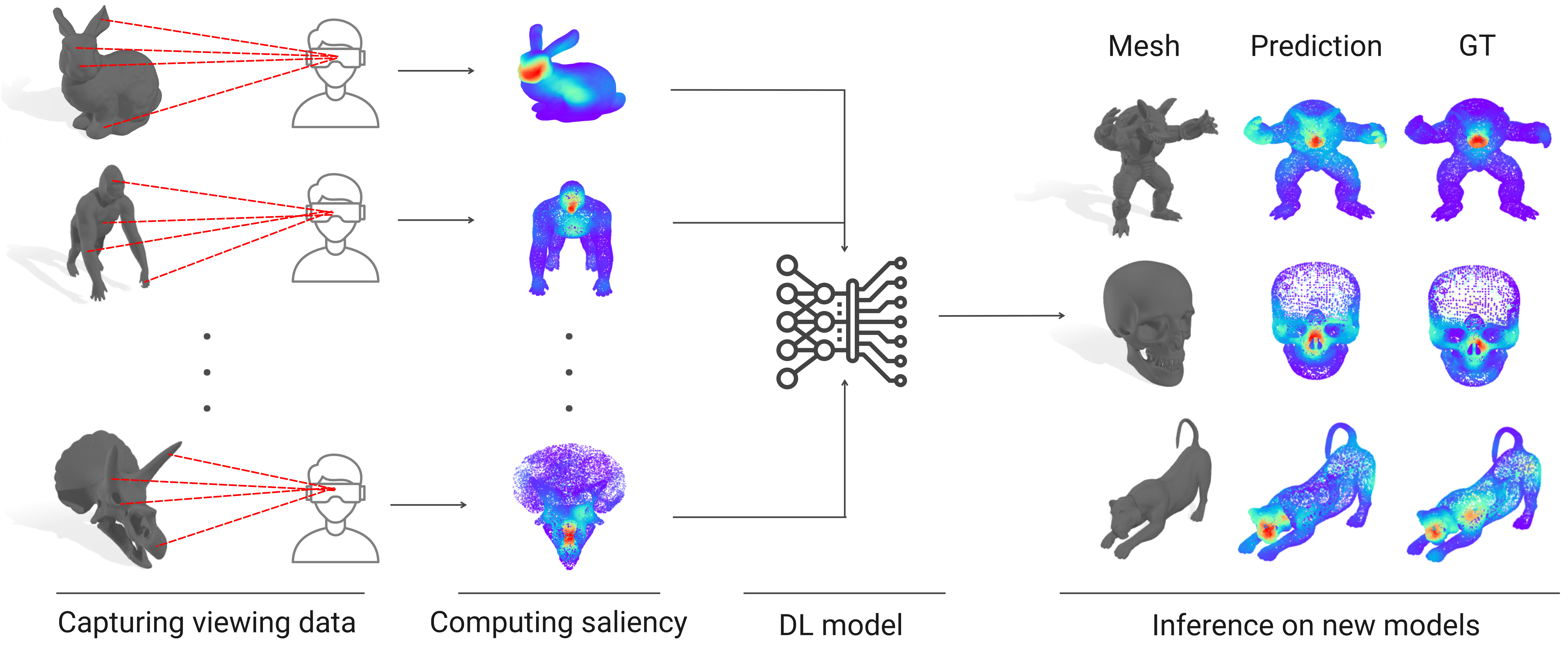
Abstract: Advances in virtual and augmented reality have increased the demand for immersive and engaging 3D experiences. To create such experiences, it is crucial to understand visual attention in 3D environments, which is typically modeled by means of saliency maps. While attention in 2D images and traditional media has been widely studied, there is still much to explore in 3D settings. In this work, we propose a deep learning-based model for predicting saliency when viewing 3D objects, which is a first step toward understanding and predicting attention in 3D environments. Previous approaches rely solely on low-level geometric cues or unnatural conditions, however, our model is trained on a dataset of real viewing data that we have manually captured, which indeed reflects actual human viewing behavior. Our approach outperforms existing state-of-the-art methods and closely approximates the ground-truth data. Our results demonstrate the effectiveness of our approach in predicting attention in 3D objects, which can pave the way for creating more immersive and engaging 3D experiences."
A Study of Change Blindness in Immersive Environments
Daniel Martin, Xin Sun, Diego Gutierrez, Belen Masia
IEEE Transactions on Visualization and Computer Graphics (IEEE VR 2023)

Abstract: Human performance is poor at detecting certain changes in a scene, a phenomenon known as change blindness. Although the exact reasons of this effect are not yet completely understood, there is a consensus that it is due to our constrained attention and memory capacity: We create our own mental, structured representation of what surrounds us, but such representation is limited and imprecise. Previous efforts investigating this effect have focused on 2D images; however, there are significant differences regarding attention and memory between 2D images and the viewing conditions of daily life. In this work, we present a systematic study of change blindness using immersive 3D environments, which offer more natural viewing conditions closer to our daily visual experience. We devise two experiments; first, we focus on analyzing how different change properties (namely type, distance, complexity, and field of view) may affect change blindness. We then further explore its relation with the capacity of our visual working memory and conduct a second experiment analyzing the influence of the number of changes. Besides gaining a deeper understanding of the change blindness effect, our results may be leveraged in several VR applications such as redirected walking, games, or even studies on saliency or attention prediction.
D-SAV360: A Dataset of Gaze Scanpaths on 360º Ambisonic Videos
Edurne Bernal-Berdun, Daniel Martin, Sandra Malpica, Pedro J. Perez, Diego Gutierrez, Belen Masia, Ana Serrano
IEEE Transactions on Visualization and Computer Graphics (ISMAR 2023)
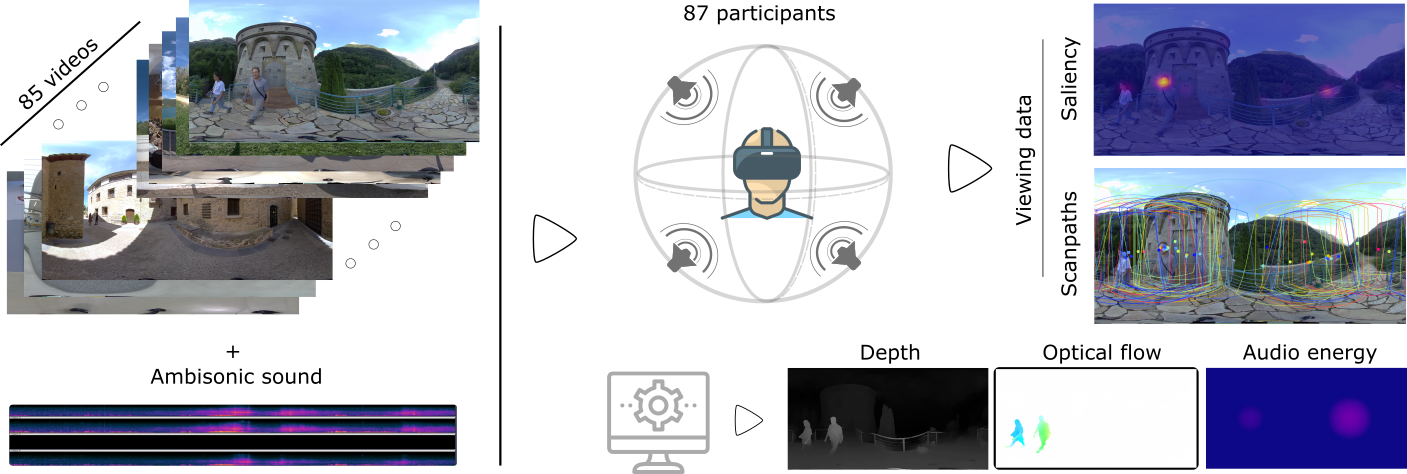
Abstract: Understanding human visual behavior within virtual reality environments is crucial to fully leverage their potential. While previous research has provided rich visual data from human observers, existing gaze datasets often suffer from the absence of multimodal stimuli. Moreover, no dataset has yet gathered eye gaze trajectories (i.e., scanpaths) for dynamic content with directional ambisonic sound, which is a critical aspect of sound perception by humans. To address this gap, we introduce D-SAV360, a dataset of 4,609 head and eye scanpaths for 360º videos with first-order ambisonics. This dataset enables a more comprehensive study of multimodal interaction on visual behavior in VR environments. We analyze our collected scanpaths from a total of 87 participants viewing 85 different videos and show that various factors such as viewing mode, content type, and gender significantly impact eye movement statistics. We demonstrate the potential of D-SAV360 as a benchmarking resource for state-of-the-art attention prediction models and discuss its possible applications in further research. By providing a comprehensive dataset of eye movement data for dynamic, multimodal virtual environments, our work can facilitate future investigations of visual behavior and attention in virtual reality.
Task-dependent Visual Behavior in Immersive Environments: A Comparative Study of Free Exploration, Memory and Visual Search
Sandra Malpica, Daniel Martin, Ana Serrano, Diego Gutierrez, Belen Masia
IEEE Transactions on Visualization and Computer Graphics (ISMAR 2023)
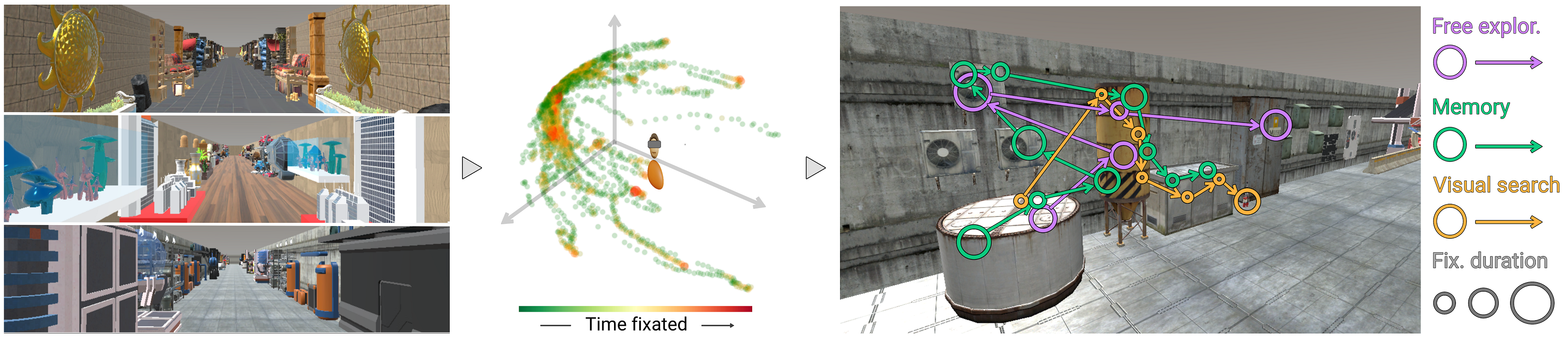
Abstract: Visual behavior depends on both bottom-up mechanisms, where gaze is driven by the visual conspicuity of the stimuli, and top-down mechanisms, guiding attention towards relevant areas based on the task or goal of the viewer. While this is well-known, visual attention models often focus mostly on bottom-up mechanisms. Existing works have analyzed the effect of high-level cognitive tasks like memory or visual search on visual behavior; however, they have done so with different stimuli, methodology, metrics and participants, which makes drawing conclusions and comparisons between tasks particularly difficult. In this work we present a systematic study of how different cognitive tasks affect visual behavior in a novel within-subjects design scheme carefully designed to avoid habituation effects. Participants performed free exploration, memory and visual search tasks in three different scenes while their eye and head movements were being recorded. We found significant, consistent differences between tasks in the distributions of fixations, saccades and head movements. Our findings can provide insights for practitioners and content creators designing task-oriented immersive applications.
ScanGAN360: A Generative Model of Realistic Scanpaths for 360º Images
Daniel Martin, Ana Serrano, Alexander W. Bergman, Gordon Wetzstein, Belen Masia
IEEE Transactions on Visualization and Computer Graphics, Vol. 28 (5), (IEEE VR 2022)

Abstract: Understanding and modeling the dynamics of human gaze behavior in 360º environments is a key challenge in computer vision and virtual reality. Generative adversarial approaches could alleviate this challenge by generating a large number of possible scanpaths for unseen images. Existing methods for scanpath generation, however, do not adequately predict realistic scanpaths for 360º images. We present ScanGAN360, a new generative adversarial approach to address this challenging problem. Our network generator is tailored to the specifics of 360º images representing immersive environments. Specifically, we accomplish this by leveraging the use of a spherical adaptation of dynamic-time warping as a loss function and proposing a novel parameterization of 360º scanpaths. The quality of our scanpaths outperforms competing approaches by a large margin and is almost on par with the human baseline. ScanGAN360 thus allows fast simulation of large numbers of virtual observers, whose behavior mimics real users, enabling a better understanding of gaze behavior and novel applications in virtual scene design.
Larger visual changes compress time: The inverted effect of asemantic visual features on interval time perception
Sandra Malpica, Belen Masia, Laura Herman, Gordon Wetzstein, David Eagleman, Diego Gutierrez, Zoya Bylinskii, Qi Sun
PLOS One (2022)
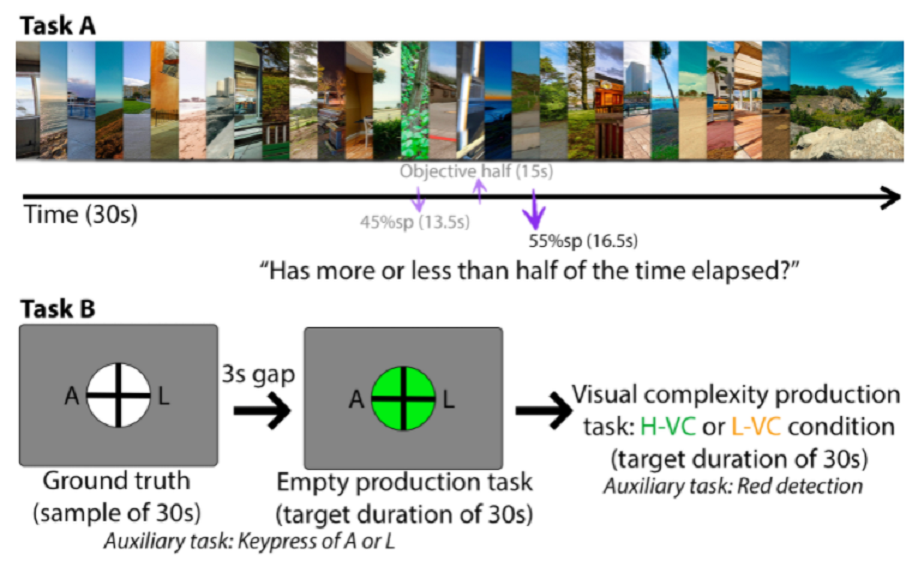
Abstract: Time perception is fluid and affected by manipulations to visual inputs. Previous literature shows that changes to low-level visual properties alter time judgments at the millisecond-level. At longer intervals, in the span of seconds and minutes, high-level cognitive effects (e.g., emotions, memories) elicited by visual inputs affect time perception, but these effects are confounded with semantic information in these inputs, and are therefore challenging to measure and control. In this work, we investigate the effect of asemantic visual properties (pure visual features devoid of emotional or semantic value) on interval time perception. Our experiments were conducted with binary and production tasks in both conventional and head-mounted displays, testing the effects of four different visual features (spatial luminance contrast, temporal frequency, field of view, and visual complexity). Our results reveal a consistent pattern: larger visual changes all shorten perceived time in intervals of up to 3 minutes, remarkably contrary to their effect on millisecond-level perception. Our findings may help alter participants' time perception, which can have broad real-world implications.
Multimodality in VR: A survey
Daniel Martin*, Sandra Malpica*, Diego Gutierrez, Belen Masia, Ana Serrano
ACM Computing Surveys (2021)

Abstract: Virtual reality has the potential to change the way we create and consume content in our everyday life. Entertainment, training, design and manufacturing, communication, or advertising are all applications that already benefit from this new medium reaching consumer level. VR is inherently different from traditional media: it offers a more immersive experience, and has the ability to elicit a sense of presence through the place and plausibility illusions. It also gives the user unprecedented capabilities to explore their environment, in contrast with traditional media. In VR, like in the real world, users integrate the multimodal sensory information they receive to create a unified perception of the virtual world. Therefore, the sensory cues that are available in a virtual environment can be leveraged to enhance the final experience. This may include increasing realism, or the sense of presence; predicting or guiding the attention of the user through the experience; or increasing their performance if the experience involves the completion of certain tasks. In this state-of-the-art report, we survey the body of work addressing multimodality in virtual reality, its role and benefits in the final user experience. The works here reviewed thus encompass several fields of research, including computer graphics, human computer interaction, or psychology and perception. Additionally, we give an overview of different applications that leverage multimodal input in areas such as medicine, training and education, or entertainment; we include works in which the integration of multiple sensory information yields significant improvements, demonstrating how multimodality can play a fundamental role in the way VR systems are designed, and VR experiences created and consumed.
SST-Sal: A Spherical Spatio-Temporal Approach for Saliency Prediction in 360º Videos
Edurne Bernal, Daniel Martin, Diego Gutierrez, Belen Masia
Computers & Graphics, Vol. 106 (CEIG), 2022
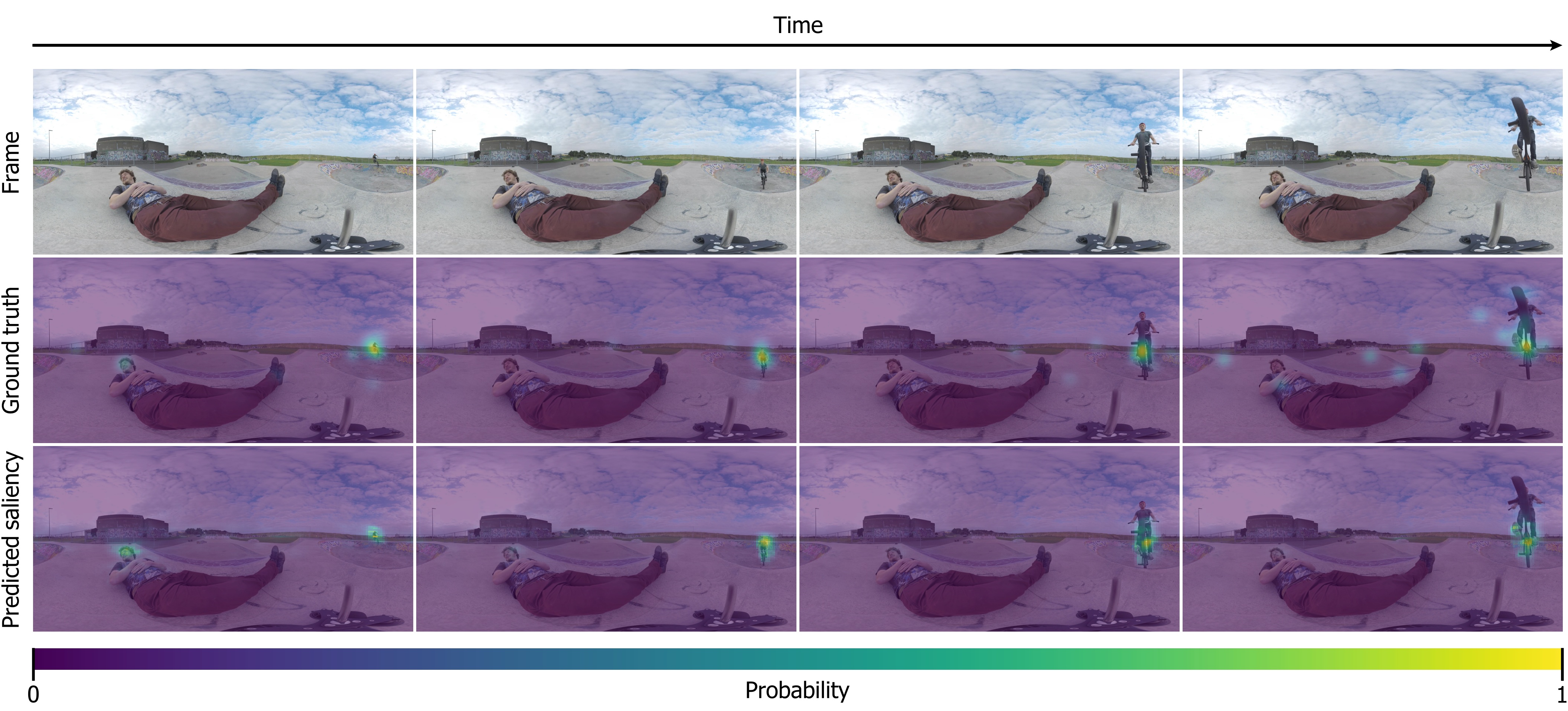
Abstract: Virtual reality (VR) has the potential to change the way people consume content, and has been predicted to become the next big computing paradigm. However, much remains unknown about the grammar and visual language of this new medium, and understanding and predicting how humans behave in virtual environments remains an open problem. In this work, we propose a novel saliency prediction model which exploits the joint potential of spherical convolutions and recurrent neural networks to extract and model the inherent spatio-temporal features from 360º videos. We employ Convolutional Long Short-Term Memory cells (ConvLSTMs) to account for temporal information at the time of feature extraction rather than to post-process spatial features as in previous works. To facilitate spatio-temporal learning, we provide the network with an estimation of the optical flow between 360º frames, since motion is known to be a highly salient feature in dynamic content. Our model is trained with a novel spherical Kullback–Leibler Divergence (KLDiv) loss function specifically tailored for saliency prediction in 360º content. Our approach outperforms previous state-of-the-art works, being able to mimic human visual attention when exploring dynamic 360º videos.
Towards assisting the decision-making process for content creators in cinematic virtual reality through the analysis of movie cuts and their influence on viewers' behavior
Carlos Marañes, Diego Gutierrez, Ana Serrano
International Transactions in Operational Research
Abstract: Virtual Reality (VR) is gaining popularity in recent years due to the commercialization of personal devices. VR is a new and exciting medium to tell stories, however, the development of Cinematic Virtual Reality (CVR) content is still in an exploratory phase. One of the main reasons is that in this medium the user has now total or partial control of the camera, therefore viewers create their own personal experiences by deciding what to see in every moment, which can potentially hinder the delivery of a pre-established narrative. In the particular case of transitions from one shot to another (movie cuts), viewers may not be aligned with the main elements of the scene placed by the content creator to convey the story. This can result in viewers missing key elements of the narrative. In this work, we explore recent studies that analyze viewers' behavior during cinematic cuts in VR videos, and we discuss guidelines and methods which can help filmmakers with the decision-making process when filming and editing their movies.
DriveRNN: Predicting Drivers’ Attention with Deep Recurrent Networks
Blanca Lasheras-Hernandez, Belen Masia, Daniel Martin
Spanish Computer Graphics Conference (CEIG), 2022

Abstract: Lately, the automotive industry has experienced a significant development led by the ambitious objective of creating an autonomous vehicle. This entails understanding driving behaviors in different environments, which usually requires gathering and analyzing large amounts of behavioral data from many drivers. However, this is usually a complex and time-consuming task, and data-driven techniques have proven to be a faster, yet robust alternative to modeling drivers’ behavior. In this work, we propose a deep learning approach to address this challenging problem. We resort to a novel convolutional recurrent architecture to learn spatio-temporal features of driving behaviors based on RGB sequences of the environment in front of the vehicle. Our model is able to predict drivers’ attention in different scenarios while outperforming competing works by a large margin.
Influence of directional sound cues on users’ exploration across 360º movie cuts
Belen Masia, Javier Camon, Diego Gutierrez, and Ana Serrano
IEEE Computer Graphics and Applications

Abstract: Virtual reality (VR) is a powerful medium for 360º storytelling, yet content creators are still in the process of developing cinematographic rules for effectively communicating stories in VR. Traditional cinematography has relied for over a century in well-established techniques for editing, and one of the most recurrent resources for this are cinematic cuts that allow content creators to seamlessly transition between scenes. One fundamental assumption of these techniques is that the content creator can control the camera, however, this assumption breaks in VR: users are free to explore the 360º around them. Recent works have studied the effectiveness of different cuts in 360º content, but the effect of directional sound cues while experiencing these cuts has been less explored. In this work, we provide the first systematic analysis of the influence of directional sound cues in users’ behavior across 360º movie cuts, providing insights that can have an impact on deriving conventions for VR storytelling.
Imperceptible manipulation of lateral camera motion for improved virtual reality applications
Ana Serrano*, Daniel Martín*, Diego Gutierrez, Karol Myszkowski, Belen Masia
ACM Transactions on Graphics, Vol. 39(6) (SIGGRAPH Asia 2020)
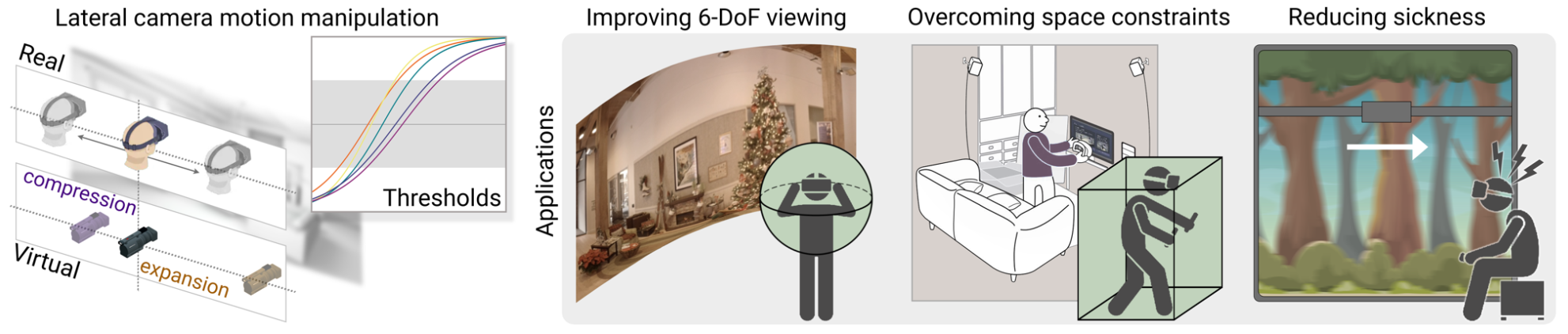
Abstract: Virtual Reality (VR) systems increase immersion by reproducing users’ move- ments in the real world. However, several works have shown that this real- to-virtual mapping does not need to be precise in order to convey a realistic experience. Being able to alter this mapping has many potential applications, since achieving an accurate real-to-virtual mapping is not always possible due to limitations in the capture or display hardware, or in the physical space available. In this work, we measure detection thresholds for lateral translation gains of virtual camera motion in response to the corresponding head motion under natural viewing, and in the absence of locomotion, so that virtual camera movement can be either compressed or expanded while these manipulations remain undetected. Finally, we propose three applications for our method, addressing three key problems in VR: improving 6-DoF viewing for captured 360◦ footage, overcoming physical constraints, and reducing simulator sickness. We have further validated our thresholds and evaluated our applications by means of additional user studies confirming that our ma- nipulations remain imperceptible, and showing that (i) compressing virtual camera motion reduces visible artifacts in 6-DoF, hence improving perceived quality, (ii) virtual expansion allows for completion of virtual tasks within a reduced physical space, and (iii) simulator sickness may be alleviated in simple scenarios when our compression method is applied.
Auditory stimuli degrade visual performance in virtual reality
Sandra Malpica, Ana Serrano, Diego Gutierrez, Belen Masia
Scientific Reports (Nature Publishing Group)
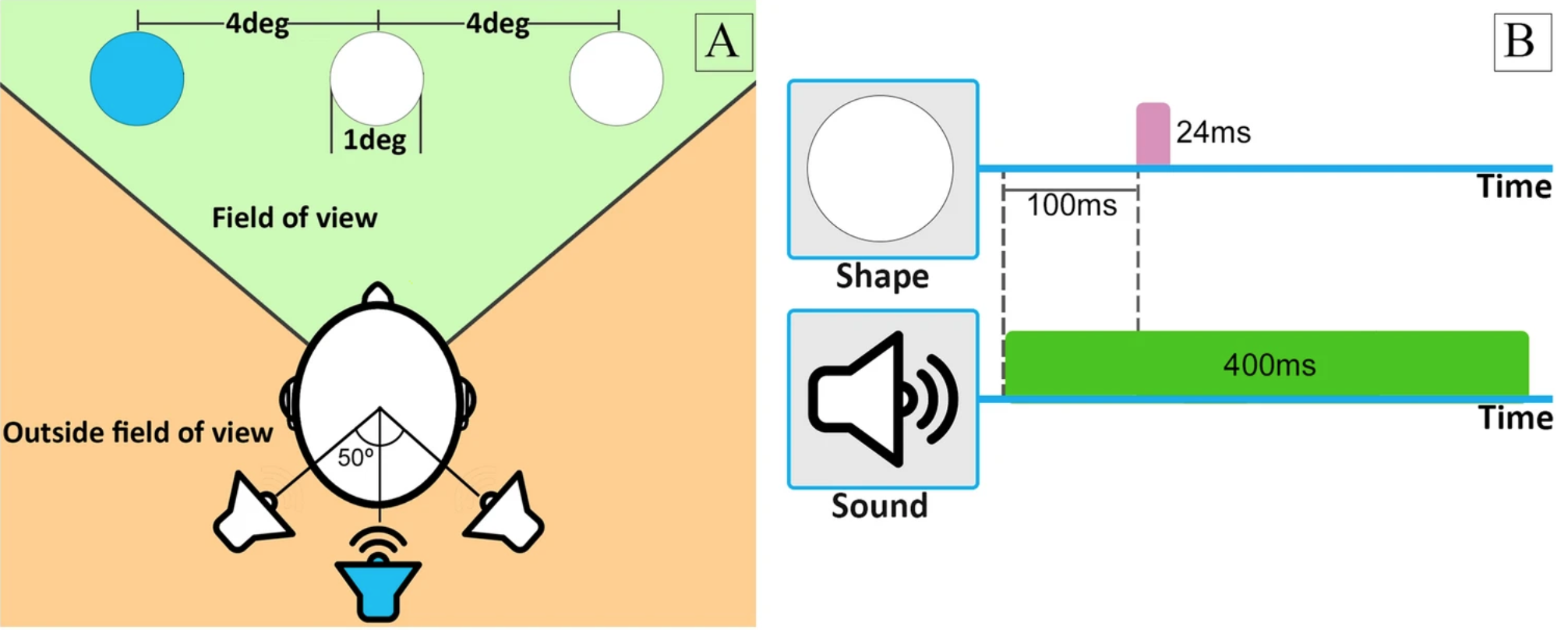
Abstract: We report an auditory effect of visual performance degradation in a virtual reality (VR) setting, where the viewing conditions are significantly different from previous studies. With the presentation of temporally congruent but spatially incongruent sound, we can degrade visual performance significantly at detection and recognition levels. We further show that this effect is robust to different types and locations of both auditory and visual stimuli. We also analyze participants behavior with an eye tracker to study the underlying cause of the degradation effect. We find that the performance degradation occurs even in the absence of saccades towards the sound source, during normal gaze behavior. This suggests that this effect is not caused by oculomotor phenomena, but rather by neural interactions or attentional shifts.
Exploring the impact of 360º movie cuts in users' attention
Carlos Marañes, Diego Gutierrez, and Ana Serrano
IEEE VR 2020

Abstract: Virtual Reality (VR) has grown since the first devices for personal use became available on the market. However, the production of cinematographic content in this new medium is still in an early exploratory phase. The main reason is that cinematographic language in VR is still under development, and we still need to learn how to tell stories effectively. A key element in traditional film editing is the use of different cutting techniques, in order to transition seamlessly from one sequence to another. A fundamental aspect of these techniques is the placement and control over the camera. However, VR content creators do not have full control of the camera. Instead, users in VR can freely explore the 360◦ of the scene around them, which potentially leads to very different experiences. While this is desirable in certain applications such as VR games, it may hinder the experience in narrative VR. In this work, we perform a systematic analysis of users’ viewing behavior across cut boundaries while watching professionally edited, narrative 360◦ videos. We extend previous metrics for quantifying user behavior in order to support more complex and realistic footage, and we introduce two new metrics that allow us to measure users’ exploration in a variety of different complex scenarios. From this analysis, (i) we confirm that previous insights derived for simple content hold for professionally edited content, and (ii) we derive new insights that could potentially influence VR content creation, informing creators about the impact of different cuts in the audience’s behavior.
Panoramic convolutions for 360º single-image saliency prediction
Daniel Martin, Ana Serrano, Belen Masia
CVPR Workshop on Computer Vision for Augmented and Virtual Reality 2020

Abstract: We present a convolutional neural network based on panoramic convolutions for saliency prediction in 360º equirectangular panoramas. Our network architecture is designed leveraging recently presented 360º-aware convolutions that represent kernels as patches tangent to the sphere where the panorama is projected, and a spherical loss function that penalizes prediction errors for each pixel depending on its coordinates in a gnomonic projection. Our model is able to successfully predict saliency in 360º scenes from a single image, outperforming other state of-the-art approaches for panoramic content, and yielding more precise results that may help in the understanding of users’ behavior when viewing 360º VR content.
Motion parallax for 360 RGBD video
Ana Serrano, Incheol Kim, Zhili Chen, Stephen DiVerdi, Diego Gutierrez, Aaron Hertzmann, Belen Masia
IEEE Transactions on Visualization and Computer Graphics, Vol. 25(5) (IEEE VR 2019)

Abstract: We present a method for adding parallax and real-time playback of 360° videos in Virtual Reality headsets. In current video players, the playback does not respond to translational head movement, which reduces the feeling of immersion, and causes motion sickness for some viewers. Given a 360° video and its corresponding depth (provided by current stereo 360 stitching algorithms), a naive image-based rendering approach would use the depth to generate a 3D mesh around the viewer, then translate it appropriately as the viewer moves their head. However, this approach breaks at depth discontinuities, showing visible distortions, while cutting the mesh at such discontinuities leads to ragged silhouettes and holes at disocclusions. We address these issues by improving the given initial depth map to yield cleaner, more natural silhouettes. We rely on a three-layer scene representation, made up of a foreground layer and two static background layers, to handle disocclusions by propagating information from multiple frames for the first background layer, and then inpainting for the second one. Our system works with input from many of today's most popular 360 stereo capture devices (e.g., Yi Halo or GoPro Odyssey), and works well even if the original video does not provide depth information. Our user studies confirm that our method provides a more compelling viewing experience, increasing immersion while reducing discomfort and nausea.
Crossmodal Perception in Virtual Reality
Sandra Malpica, Ana Serrano, Marcos Allue, Manuel Bedia, Belen Masia
Multimedia Tools and Applications, 2019
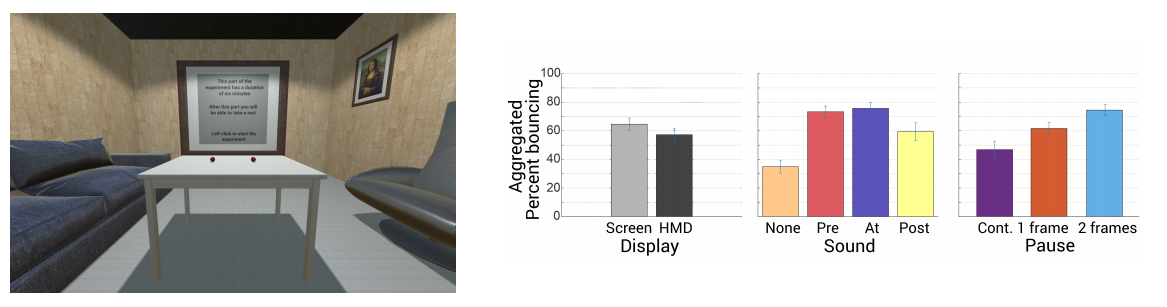
Abstract: With the proliferation of low-cost, consumer level, head-mounted displays (HMDs) we are witnessing a reappearance of virtual reality. However, there are still important stumbling blocks that hinder the achievable visual quality of the results. Knowledge of human perception in virtual environments can help overcome these limitations. In this work, within the much-studied area of perception in virtual environments, we look into the less explored area of crossmodal perception, that is, the interaction of different senses when perceiving the environment. In particular, we look at the influence of sound on visual perception in a virtual reality scenario. First, we assert the existence of a crossmodal visuo-auditory effect in a VR scenario through two experiments, and find that, similar to what has been reported in conventional displays, our visual perception is affected by auditory stimuli in a VR setup. The crossmodal effect in VR is, however, lower than that present in a conventional display counterpart. Having asserted the effect, a third experiment looks at visuo-auditory crossmodality in the context of material appearance perception. We test different rendering qualities, together with the presence of sound, for a series of materials. The goal of the third experiment is twofold: testing whether known interactions in traditional displays hold in VR, and finding insights that can have practical applications in VR content generation (e.g., by reducing rendering costs)
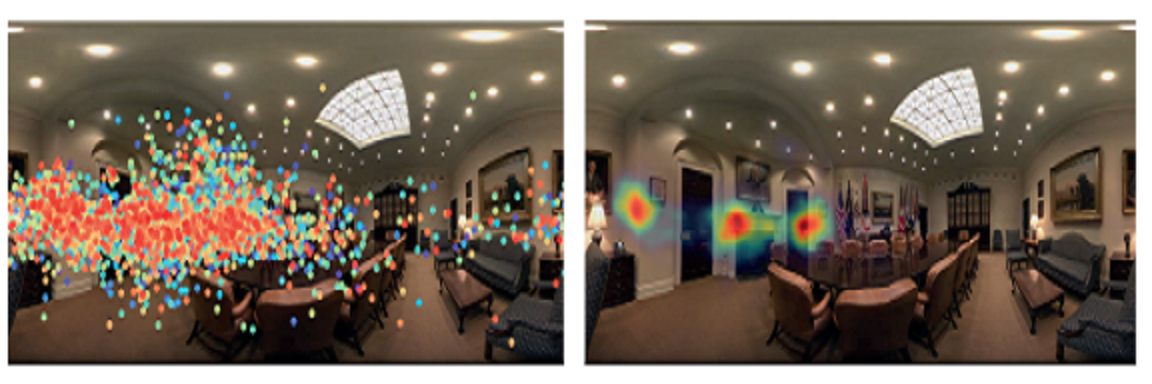
How do people explore virtual environments?
Vincent Sitzmann*, Ana Serrano*, Amy Pavel, Maneesh Agrawala, Diego Gutierrez, Belen Masia, and Gordon Wetzstein
IEEE Transactions on Visualization and Computer Graphics, Vol. 24(4) (IEEE VR 2018)
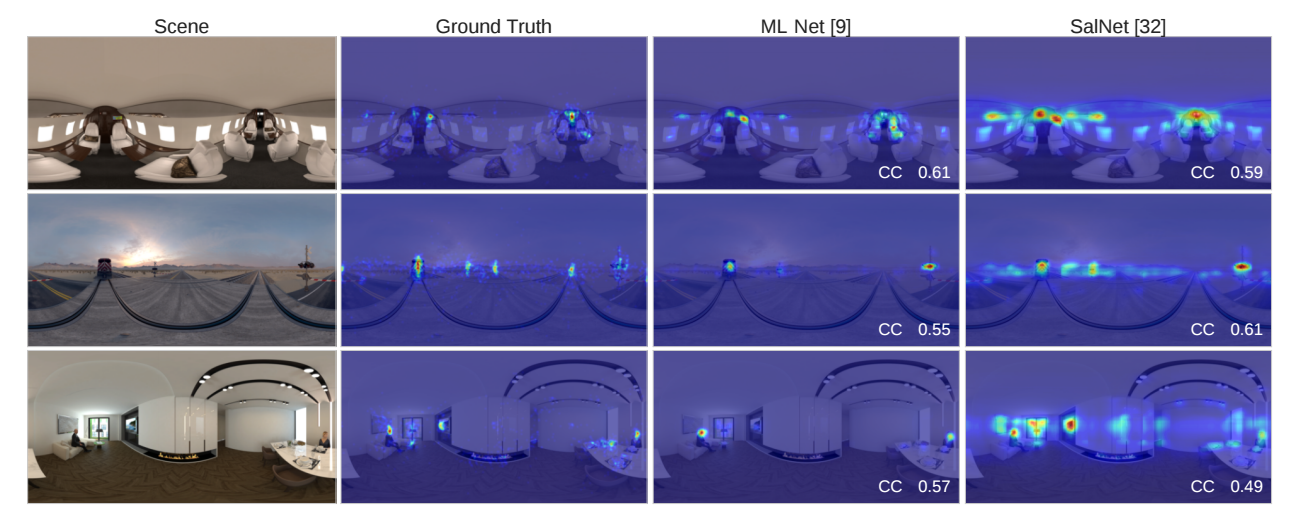
Abstract: Understanding how humans explore virtual environments is crucial for many applications, such as developing compression algorithms or designing effective cinematic virtual reality (VR) content, as well as to develop predictive computational models. We have recorded 780 head and gaze trajectories from 86 users exploring omnidirectional stereo panoramas using VR head-mounted displays. By analyzing the interplay between visual stimuli, head orientation, and gaze direction, we demonstrate patterns and biases of how people explore these panoramas and we present first steps toward predicting time-dependent saliency. To compare how visual attention and saliency in VR are different from conventional viewing conditions, we have also recorded users observing the same scenes in a desktop setup. Based on this data, we show how to adapt existing saliency predictors to VR, so that insights and tools developed for predicting saliency in desktop scenarios may directly transfer to these immersive applications.
Movie Editing and Cognitive Event Segmentation in Virtual Reality Video
Ana Serrano, Vincent Sitzmann, Jaime Ruiz-Borau, Gordon Wetzstein, Diego Gutierrez, Belen Masia
ACM Transactions on Graphics, Vol. 36(4) (SIGGRAPH 2017)

Abstract: Traditional cinematography has relied for over a century on a well-established set of editing rules, called continuity editing, to create a sense of situational continuity. Despite massive changes in visual content across cuts, viewers in general experience no trouble perceiving the discontinuous flow of information as a coherent set of events. However, Virtual Reality (VR) movies are intrinsically different from traditional movies in that the viewer controls the camera orientation at all times. As a consequence, common editing techniques that rely on camera orientations, zooms, etc., cannot be used. In this paper we investigate key relevant questions to understand how well traditional movie editing carries over to VR, such as: Does the perception of continuity hold across edit boundaries? Under which conditions? Does viewers’ observational behavior change after the cuts? To do so, we rely on recent cognition studies and the event segmentation theory, which states that our brains segment continuous actions into a series of discrete, meaningful events. We first replicate one of these studies to assess whether the predictions of such theory can be applied to VR. We next gather gaze data from viewers watching VR videos containing different edits with varying parameters, and provide the first systematic analysis of viewers’ behavior and the perception of continuity in VR. From this analysis we make a series of relevant findings; for instance, our data suggests that predictions from the cognitive event segmentation theory are useful guides for VR editing; that different types of edits are equally well understood in terms of continuity; and that spatial misalignments between regions of interest at the edit boundaries favor a more exploratory behavior even after viewers have fixated on a new region of interest. In addition, we propose a number of metrics to describe viewers’ attentional behavior in VR. We believe the insights derived from our work can be useful as guidelines for VR content creation.
Crossmodal perception in immersive environments
Marcos Allue, Ana Serrano, Manuel G. Bedia, Belen Masia
Spanish Computer Graphics Conference (CEIG), 2016
Abstract: With the proliferation of low-cost, consumer level, head-mounted displays (HMDs) such as Oculus VR or Sony’s Morpheus, we are witnessing a reappearance of virtual reality. However, there are still important stumbling blocks that hinder the development of applications and reduce the visual quality of the results. Knowledge of human perception in virtual environments can help overcome these limitations. In this paper, within the much-studied area of perception in virtual environments, we chose to look into the less explored area of crossmodal perception, that is, the interaction of different senses when perceiving the environment. In particular, we looked at the influence of sound on visual motion perception in a virtual reality scenario. We first replicated a well-known crossmodal perception experiment, carried out on a conventional 2D display, and then extended it to a 3D headmounted display (HMD). Next, we performed an additional experiment in which we increased the complexity of the stimuli of the previous experiment, to test whether the effects observed would hold in more realistic scenes. We found that the trend which was previously observed in 2D displays is maintained in HMDs, but with an observed reduction of the crossmodal effect. With more complex stimuli the trend holds, and the crossmodal effect is further reduced, possibly due to the presence of additional visual cues.