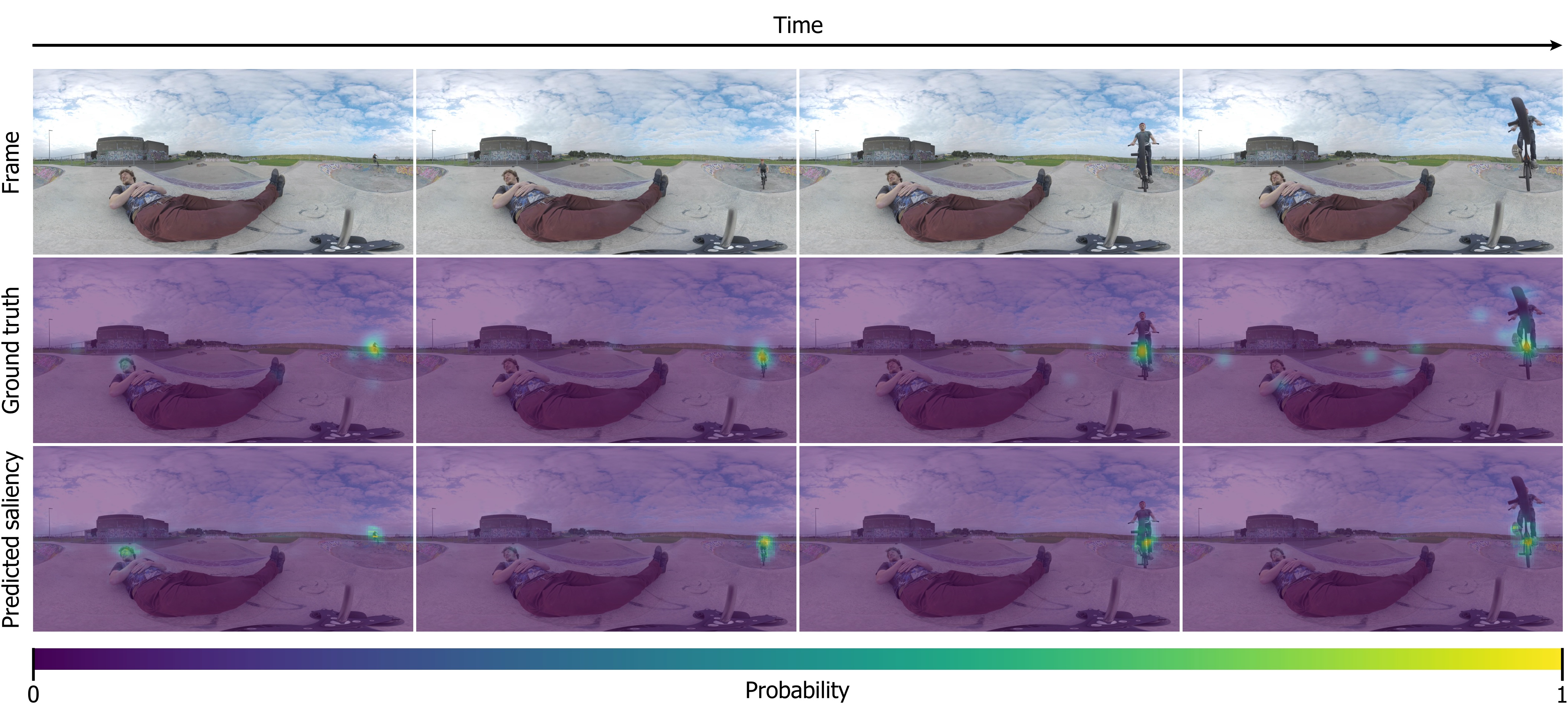
Virtual reality (VR) has the potential to change the way people consume content, and has been predicted to become the next big computing paradigm. However, much remains unknown about the grammar and visual language of this new medium, and understanding and predicting how humans behave in virtual environments remains an open problem. In this work, we propose a novel saliency prediction model which exploits the joint potential of spherical convolutions and recurrent neural networks to extract and model the inherent spatio-temporal features from 360º videos. We employ Convolutional Long Short-Term Memory cells (ConvLSTMs) to account for temporal information at the time of feature extraction rather than to post-process spatial features as in previous works. To facilitate spatio-temporal learning, we provide the network with an estimation of the optical flow between 360º frames, since motion is known to be a highly salient feature in dynamic content. Our model is trained with a novel spherical Kullback–Leibler Divergence (KLDiv) loss function specifically tailored for saliency prediction in 360º content. Our approach outperforms previous state-of-the-art works, being able to mimic human visual attention when exploring dynamic 360º videos.
@article{Bernal-Berdun2022,
title = {SST-Sal: A spherical spatio-temporal approach for saliency prediction in 360 $^{\circ}$ videos},
journal = {Computers & Graphics},
year = {2022},
volume = {106},
pages = {200-209},
issn = {0097-8493},
doi = {https://doi.org/10.1016/j.cag.2022.06.002},
url = {https://www.sciencedirect.com/science/article/pii/S0097849322001042},
author = {Edurne Bernal-Berdun and Daniel Martin and Diego Gutierrez and Belen Masia},
keywords = {Virtual reality, Scene Understanding, Saliency},
abstract = {Virtual reality (VR) has the potential to change the way people consume content, and has been predicted to become the next big computing paradigm. However, much remains unknown about the grammar and visual language of this new medium, and understanding and predicting how humans behave in virtual environments remains an open problem. In this work, we propose a novel saliency prediction model which exploits the joint potential of spherical convolutions and recurrent neural networks to extract and model the inherent spatio-temporal features from 360$^{\circ}$ videos. We employ Convolutional Long Short-Term Memory cells (ConvLSTMs) to account for temporal information at the time of feature extraction rather than to post-process spatial features as in previous works. To facilitate spatio-temporal learning, we provide the network with an estimation of the optical flow between 360$^{\circ}$ frames, since motion is known to be a highly salient feature in dynamic content. Our model is trained with a novel spherical Kullback-Leibler Divergence (KLDiv) loss function specifically tailored for saliency prediction in 360$^{\circ}$ content. Our approach outperforms previous state-of-the-art works, being able to mimic human visual attention when exploring dynamic 360$^{\circ}$ videos.}
}
@article{martin2022scangan360,
title={ScanGAN360: A Generative Model of Realistic Scanpaths for 360° Images},
author={Martin, Daniel and Serrano, Ana and Bergman, Alexander W and Wetzstein, Gordon and Masia, Belen},
journal={IEEE Transactions on Visualization and Computer Graphics},
volume={28},
number={5},
pages={2003--2013},
year={2022},
publisher={IEEE}
}
@inproceedings{martin20saliency,
author={Martin, Daniel and Serrano, Ana and Masia, Belen},
title={Panoramic convolutions for $360^{\circ}$ single-image saliency prediction},
booktitle={CVPR Workshop on Computer Vision for Augmented and Virtual Reality},
year={2020}
}