Visual Appearance: Perception and Editing
Computer-generated imagery is now ubiquitous in our society, spanning fields such as games and movies, architecture, engineering, or virtual prototyping, while also helping create novel ones such as computational materials. With the increase in computational power and the improvement of acquisition techniques, there has been a paradigm shift in the field towards data-driven techniques, which has yielded an unprecedented level of realism in visual appearance.
Unfortunately, this leads to a series of problems: First, there is a disconnect between the mathematical representation of the data and any meaningful parameters that humans understand; the captured data is machine-friendly, but not human friendly. Second, the many different acquisition systems lead to heterogeneous formats and very large datasets. And third, real world appearance functions are usually nonlinear and high-dimensional. As a result, visual appearance datasets are increasingly unfit to editing operations, which limits the creative process for scientists, engineers, artists and practitioners in general. There is an immense gap between the complexity, realism and richness of the captured data, and the flexibility to edit such data. This line of research plans to bridge this gap, putting the user at the core. Achieving our goals will finally enable us to reach the true potential of real-world captured datasets in many aspects of society.
Funding agencies


Publications
Fine-Grained Spatially Varying Material Selection in Images
Julia Guerrero-Viu, Michael Fischer, Iliyan Georgiev, Elena Garces, Diego Gutierrez, Belen Masia, Valentin Deschaintre
ACM Transactions on Graphics (Proc. SIGGRAPH Asia 2025)

Abstract: Selection is the first step in many image editing processes, enabling faster and simpler modifications of all pixels sharing a common modality. In this work, we present a method for material selection in images, robust to lighting and reflectance variations, which can be used for downstream editing tasks. We rely on vision transformer (ViT) models and leverage their features for selection, proposing a multi-resolution processing strategy that yields finer and more stable selection results than prior methods. Furthermore, we enable selection at two levels: texture and subtexture, leveraging a new two-level material selection (DuMaS) dataset which includes dense annotations for over 800,000 synthetic images, both on the texture and subtexture levels.
Artist-Inator: Text-based, Gloss-aware Non-photorealistic Stylization
J. Daniel Subias, Saul Daniel-Soriano, Diego Gutierrez, Ana Serrano
Computer Graphics Forum (EGSR 2025)

Abstract: Large diffusion models have made a remarkable leap synthesizing high-quality artistic images from text descriptions. However, these powerful pre-trained models still lack control to guide key material appearance properties, such as gloss. In this work, we present a threefold contribution: (1) we analyze how gloss is perceived across different artistic styles (i.e., oil painting, watercolor, ink pen, charcoal, and soft crayon); (2) we leverage our findings to create a dataset with 1,336,272 stylized images of many different geometries in all five styles, including automatically-computed text descriptions of their appearance (e.g., "A glossy bunny hand painted with an orange soft crayon'); and (3) we train ControlNet to condition Stable Diffusion XL synthesizing novel painterly depictions of new objects, using simple inputs such as edge maps, hand-drawn sketches, or clip arts. Compared to previous approaches, our framework yields more accurate results despite the simplified input, as we show both quantitative and qualitatively.
A Controllable Appearance Representation for Flexible Transfer and Editing
Santiago Jimenez-Navarro, Julia Guerrero-Viu, Belen Masia
Eurographics Symposium on Rendering (EGSR), 2025

Abstract: We present a method that computes an interpretable representation of material appearance within a highly compact, disentangled latent space. This representation is learned in a self-supervised fashion using a VAE-based model. We train our model with a carefully designed unlabeled dataset, avoiding possible biases induced by human-generated labels. Our model demonstrates strong disentanglement and interpretability by effectively encoding material appearance and illumination, despite the absence of explicit supervision. To showcase the capabilities of such a representation, we leverage it for two proof-of-concept applications: image-based appearance transfer and editing. Our representation is used to condition a diffusion pipeline that transfers the appearance of one or more images onto a target geometry, and allows the user to further edit the resulting appearance. This approach offers fine-grained control over the generated results: thanks to the well-structured compact latent space, users can intuitively manipulate attributes such as hue or glossiness in image space to achieve the desired final appearance.
TexSliders: Diffusion-Based Texture Editing in CLIP Space
Julia Guerrero-Viu, Miloš Hašan, Arthur Roullier, Midhun Harikumar, Yiwei Hu, Paul Guerrero, Diego Gutierrez, Belen Masia, Valentin Deschaintre
SIGGRAPH 2024

Abstract: Generative models have enabled intuitive image creation and manipulation using natural language. In particular, diffusion models have recently shown remarkable results for natural image editing. In this work, we propose to apply diffusion techniques to edit textures, a specific class of images that are an essential part of 3D content creation pipelines. We analyze existing editing methods and show that they are not directly applicable to textures, since their common underlying approach, manipulating attention maps, is unsuitable for the texture domain. To address this, we propose a novel approach that instead manipulates CLIP image embeddings to condition the diffusion generation. We define editing directions using simple text prompts (e.g., "aged wood" to "new wood") and map these to CLIP image embedding space using a texture prior, with a sampling-based approach that gives us identity-preserving directions in CLIP space. To further improve identity preservation, we project these directions to a CLIP subspace that minimizes identity variations resulting from entangled texture attributes. Our editing pipeline facilitates the creation of arbitrary sliders using natural language prompts only, with no ground-truth annotated data necessary."
Studying the Effect of Material and Geometry on Perceptual Outdoor Illumination
Miao Wang, Jin-Chao Zhou, Wei-Qi Feng, Yu-Zhu Jiang, and Ana Serrano
IEEE TVCG

Abstract: Understanding and modeling perceived properties of sky-dome illumination is an important but challenging problem due to the interplay of several factors such as the materials and geometries of the objects present in the scene being observed. Existing models of sky-dome illumination focus on the physical properties of the sky. However, these parametric models often do not align well with the properties perceived by a human observer. In this work, drawing inspiration from the Hosek-Wilkie sky-dome model, we investigate the perceptual properties of outdoor illumination. For this purpose, we perform a large-scale user study via crowdsourcing to collect a dataset of perceived illumination properties (scattering, glare, and brightness) for different combinations of geometries and materials under a variety of outdoor illuminations, totaling 5,000 distinct images. We perform a thorough statistical analysis of the collected data which reveals several interesting effects. For instance, our analysis shows that when there are objects in the scene made of rough materials, the perceived scattering of the sky increases. Furthermore, we utilize our extensive collection of images and their corresponding perceptual attributes to train a predictor. This predictor, when provided with a single image as input, generates an estimation of perceived illumination properties that align with human perceptual judgments. Accurately estimating perceived illumination properties can greatly enhance the overall quality of integrating virtual objects into real scene photographs. Consequently, we showcase various applications of our predictor. For instance, we demonstrate its utility as a luminance editing tool for showcasing virtual objects in outdoor scenes.
Navigating the Manifold of Translucent Appearance
Dario Lanza, Adrian Jarabo y Belen Masia
Computer Graphics Forum (Eurographics 2024)

Abstract: This work presents a perceptually-motivated manifold for translucent appearance, designed for intuitive editing of translucent materials by navigating through the manifold. Classic tools for editing translucent appearance, based on the use of sliders to tune a number of parameters, are challenging for non-expert users: these parameters have a highly non-linear effect on appearance, and exhibit complex interplay and similarity relations between them. Instead, we pose editing as a navigation task in a low-dimensional space of appearances, which abstracts the user from the underlying optical parameters. To achieve this, we build a low-dimensional continuous manifold of translucent appearances that correlates with how humans perceive these types of materials. We first analyze the correlation of different distance metrics with human perception. We select the best-performing metric to build a low-dimensional manifold, which can be used to navigate the space of translucent appearance. To evaluate the validity of our proposed manifold within its intended application scenario, we build an editing interface that leverages the manifold, and relies on image navigation plus a fine-tuning step to edit appearance. We compare our intuitive interface to a traditional, slider-based one in a user study, demonstrating its effectiveness and superior performance when editing translucent objects.
Predicting Perceived Gloss: Do Weak Labels Suffice?
Julia Guerrero-Viu* , J. Daniel Subias* , Ana Serrano, Katherine R. Storrs, Roland W. Fleming, Belen Masia, Diego Gutierrez
Computer Graphics Forum (Eurographics 2024)
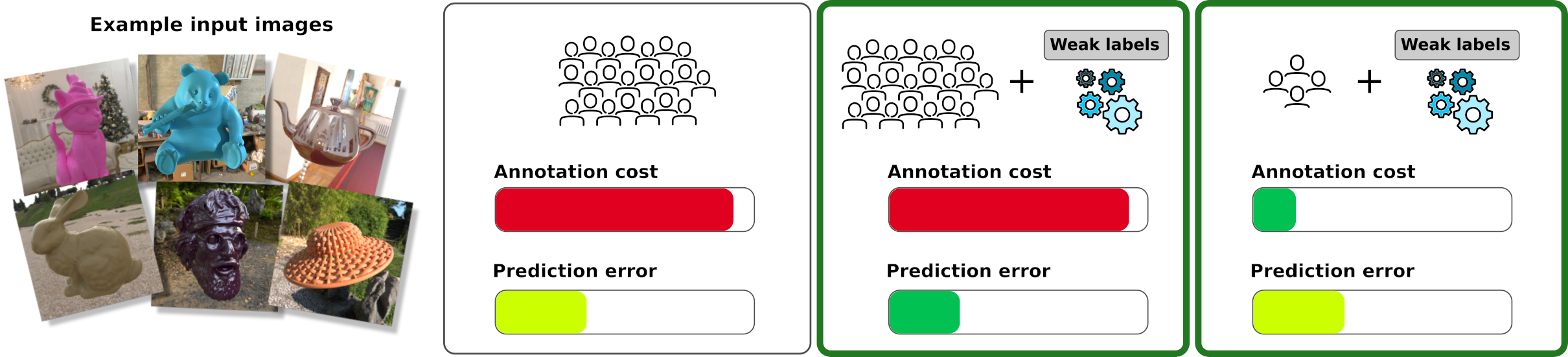
Abstract: Estimating perceptual attributes of materials directly from images is a challenging task due to their complex, not fully-understood interactions with external factors, such as geometry and lighting. Supervised deep learning models have recently been shown to outperform traditional approaches, but rely on large datasets of human-annotated images for accurate perception predictions. Obtaining reliable annotations is a costly endeavor, aggravated by the limited ability of these models to generalise to different aspects of appearance. In this work, we show how a much smaller set of human annotations (strong labels) can be effectively augmented with automatically derived weak labels in the context of learning a low-dimensional image-computable gloss metric. We evaluate three alternative weak labels for predicting human gloss perception from limited annotated data. Incorporating weak labels enhances our gloss prediction beyond the current state of the art. Moreover, it enables a substantial reduction in human annotation costs without sacrificing accuracy, whether working with rendered images or real photographs.
Cinematic Gaussians: Real-Time HDR Radiance Fields with Depth of Field
Chao Wang, Krzysztof Wolski, Bernhard Kerbl, Ana Serrano, Mojtaba Bemana, Hans-Peter Seidel, Karol Myszkowski, Thomas Leimkühler
Computer Graphics Forum (Pacific Graphics 2024)

Abstract: Radiance field methods represent the state of the art in reconstructing complex scenes from multi-view photos. However, these reconstructions often suffer from one or both of the following limitations: First, they typically represent scenes in low dynamic range (LDR), which restricts their use to evenly lit environments and hinders immersive viewing experiences. Secondly, their reliance on a pinhole camera model, assuming all scene elements are in focus in the input images, presents practical challenges and complicates refocusing during novel-view synthesis. Addressing these limitations, we present a lightweight method based on 3D Gaussian Splatting that utilizes multi-view LDR images of a scene with varying exposure times, apertures, and focus distances as input to reconstruct a high-dynamic-range (HDR) radiance field. By incorporating analytical convolutions of Gaussians based on a thin-lens camera model as well as a tonemapping module, our reconstructions enable the rendering of HDR content with flexible refocusing capabilities. We demonstrate that our combined treatment of HDR and depth of field facilitates real-time cinematic rendering, outperforming the state of the art.
The Visual Language of Fabrics
Valentin Deschaintre*, Julia Guerrero-Viu*, Diego Gutierrez, Tamy Boubekeur, Belen Masia
ACM Transactions on Graphics (Proc. SIGGRAPH 2023)

Abstract: We introduce text2fabric, a novel dataset that links free-text descriptions to various fabric materials. The dataset comprises 15,000 natural language descriptions associated to 3,000 corresponding images of fabric materials. Traditionally, material descriptions come in the form of tags/keywords, which limits their expressivity, induces pre-existing knowledge of the appropriate vocabulary, and ultimately leads to a chopped description system. Therefore, we study the use of free-text as a more appropriate way to describe material appearance, taking the use case of fabrics as a common item that non-experts may often deal with. Based on the analysis of the dataset, we identify a compact lexicon, set of attributes and key structure that emerge from the descriptions. This allows us to accurately understand how people describe fabrics and draw directions for generalization to other types of materials. We also show that our dataset enables specializing large vision-language models such as CLIP, creating a meaningful latent space for fabric appearance, and significantly improving applications such as fine-grained material retrieval and automatic captioning.
An Implicit Neural Representation for the Image Stack: Depth, All in Focus, and High Dynamic Range
Chao Wang, Ana Serrano, Xingang Pan, Krzysztof Wolski, Bin Chen, Karol Myszkowski, Hans-Peter Seidel, Christian Theobalt, Thomas Leimkühler
ACM Transactions on Graphics (Proc. SIGGRAPH Asia 2023)

Abstract: In everyday photography, physical limitations of camera sensors and lenses frequently lead to a variety of degradations in captured images such as saturation or defocus blur. A common approach to overcome these limitations is to resort to image stack fusion, which involves capturing multiple images with different focal distances or exposures. For instance, to obtain an all-in-focus image, a set of multi-focus images is captured. Similarly, capturing multiple exposures allows for the reconstruction of high dynamic range. In this paper, we present a novel approach that combines neural fields with an expressive camera model to achieve a unified reconstruction of an all-in-focus high-dynamic-range image from an image stack. Our approach is composed of a set of specialized implicit neural representations tailored to address specific sub-problems along our pipeline: We use neural implicits to predict flow to overcome misalignments arising from lens breathing, depth, and all-in-focus images to account for depth of field, as well as tonemapping to deal with sensor responses and saturation -- all trained using a physically inspired supervision structure with a differentiable thin lens model at its core. An important benefit of our approach is its ability to handle these tasks simultaneously or independently, providing flexible post-editing capabilities such as refocusing and exposure adjustment. By sampling the three primary factors in photography within our framework (focal distance, aperture, and exposure time), we conduct a thorough exploration to gain valuable insights into their significance and impact on overall reconstruction quality. Through extensive validation, we demonstrate that our method outperforms existing approaches in both depth-from-defocus and all-in-focus image reconstruction tasks. Moreover, our approach exhibits promising results in each of these three dimensions, showcasing its potential to enhance captured image quality and provide greater control in post-processing.
The effect of display capabilities on the gloss consistency between real and virtual objects
Bin Chen*, Akshay Jindal*, Michal Piovarči, Chao Wang, Hans-Peter Seidel, Piotr Didyk, Karol Myszkowski, Ana Serrano, and Rafał K. Mantiuk
SIGGRAPH Asia 2023

Abstract: A faithful reproduction of gloss is inherently difficult because of the limited dynamic range, peak luminance, and 3D capabilities of display devices. This work investigates how the display capabilities affect gloss appearance with respect to a real-world reference object. To this end, we employ an accurate imaging pipeline to achieve a perceptual gloss match between a virtual and real object presented side-by-side on an augmented-reality high-dynamic-range (HDR) stereoscopic display, which has not been previously attained to this extent. Based on this precise gloss reproduction, we conduct a series of gloss matching experiments to study how gloss perception degrades based on individual factors: object albedo, display luminance, dynamic range, stereopsis, and tone mapping. We support the study with a detailed analysis of individual factors, followed by an in-depth discussion on the observed perceptual effects. Our experiments demonstrate that stereoscopic presentation has a limited effect on the gloss matching task on our HDR display. However, both reduced luminance and dynamic range of the display reduce the perceived gloss. This means that the visual system cannot compensate for the changes in gloss appearance across luminance (lack of gloss constancy), and the tone mapping operator should be carefully selected when reproducing gloss on a low dynamic range (LDR) display.
In-the-wild Material Appearance Editing using Perceptual Attributes
J. Daniel Subias, Manuel Lagunas
Computer Graphics Forum (Eurographics 2023)

Abstract: Intuitively editing the appearance of materials from a single image is a challenging task given the complexity of the interactions between light and matter, and the ambivalence of human perception. This problem has been traditionally addressed by estimating additional factors of the scene like geometry or illumination, thus solving an inverse rendering problem and subduing the final quality of the results to the quality of these estimations. We present a single-image appearance editing framework that allows us to intuitively modify the material appearance of an object by increasing or decreasing high-level perceptual attributes describing such appearance (e.g., glossy or metallic). Our framework takes as input an in-the-wild image of a single object, where geometry, material, and illumination are not controlled, and inverse rendering is not required. We rely on generative models and devise a novel architecture with Selective Transfer Unit (STU) cells that allow to preserve the high-frequency details from the input image in the edited one. To train our framework we leverage a dataset with pairs of synthetic images rendered with physically-based algorithms, and the corresponding crowd-sourced ratings of high-level perceptual attributes. We show that our material editing framework outperforms the state of the art, and showcase its applicability on synthetic images, in-the-wild real-world photographs, and video sequences.
GlowGAN: Unsupervised Learning of HDR Images from LDR Images in the Wild
Chao Wang, Ana Serrano, Xingang Pan, Bin Chen, Karol Myszkowski, Hans-Peter Seidel, Christian Theobalt and Thomas Leimkühler
Proceeding of International Conference on Computer Vision (ICCV) 2023

Abstract: Most in-the-wild images are stored in Low Dynamic Range (LDR) form, serving as a partial observation of the High Dynamic Range (HDR) visual world.Despite limited dynamic range, these LDR images are often captured with different exposures, implicitly containing information about the underlying HDR image distribution.Inspired by this intuition, in this work we present, to the best of our knowledge, the first method for learning a generative model of HDR images from in-the-wild LDR image collections in a fully unsupervised manner. The key idea is to train a generative adversarial network (GAN) to generate HDR images which, when projected to LDR under various exposures, are indistinguishable from real LDR images.The projection from HDR to LDR is achieved via a camera model that captures the stochasticity in exposure and camera response function.Experiments show that our method GlowGAN can synthesize photorealistic HDR images in many challenging cases such as landscapes, lightning, or windows, where previous supervised generative models produce overexposed images. With the assistance of GlowGAN, we showcase the novel application of unsupervised inverse tone mapping (GlowGAN-ITM) that sets a new paradigm in this field. Unlike previous methods that gradually complete information from LDR input, GlowGAN-ITM searches the entire HDR image manifold modeled by GlowGAN for the HDR images which can be mapped back to the LDR input. GlowGAN-ITM achieves more realistic reconstruction of overexposed regions compared to state-of-the-art supervised learning models, despite not requiring HDR images or paired multi-exposure images for training.
Towards latent representations of gloss in complex stimuli using unsupervised learning
Julia Guerrero-Viu, Ana Serrano, Belen Masia, Diego Gutierrez
Vision Science Society (VSS) Poster, 2023
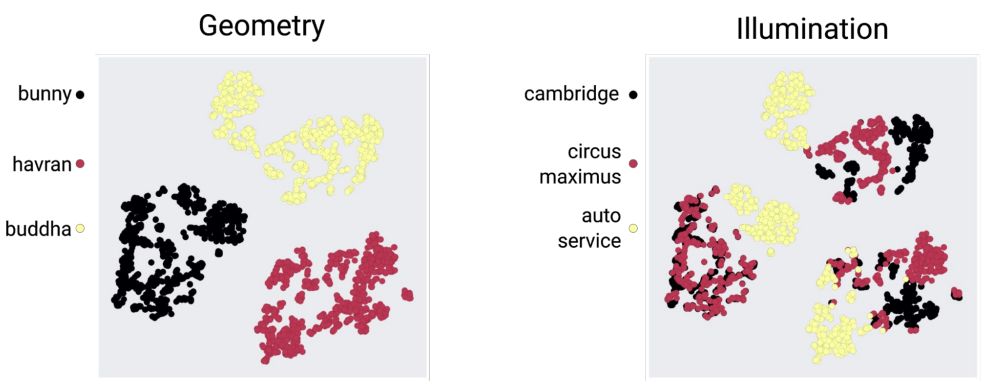
Abstract: Our visual perception of the world is strongly influenced by material appearance. Humans can easily recognize and discriminate materials, despite the influence on their final appearance of confounding factors such as illumination or surface geometry. However, understanding material appearance and perceived properties such as glossiness remains challenging. Recent literature has shown how unsupervised generative neural networks can spontaneously learn perceptually-meaningful latent representations from simple stimuli renderings of bumpy surfaces, and cluster them according to glossiness despite receiving no explicit information about it. Furthermore, those representations correlate better with human perception of gloss than the physical parameters of the materials, suggesting that our brains may decipher glossiness by learning the statistical structure of images. In this work, we analyze the performance of such unsupervised learning models on a wider variety of complex real-world images, including realistic object geometries, real environment maps, and measured materials. We train a PixelVAE generative network in an unsupervised manner on a dataset containing three different geometries under three different illuminations, using more than 300 materials. We study the latent representations found by our model without receiving any prior knowledge. Our results show that the model clusters the stimuli hierarchically, suggesting that geometry could be the most relevant appearance factor, followed by illumination. This is different from previous experiments using abstract bumpy surfaces, where the role of geometry was less prominent due to the randomness of the bumps. Finally, we analyze how our (unsupervised) learned latent representations correlate with human ratings of glossiness perception, showing a reasonable organization despite the complex interactions with geometry and lightness. In conclusion, our results suggest that unsupervised learning representations may help to understand human visual perception of material appearance even in the presence of complex stimuli.
Gloss management for consistent reproduction of real and virtual objects
Bin Chen, Michal Piovarci, Chao Wang, Hans-Peter Seidel, Piotr Didyk, Karol Myszkowski, Ana Serrano
SIGGRAPH Asia 2022
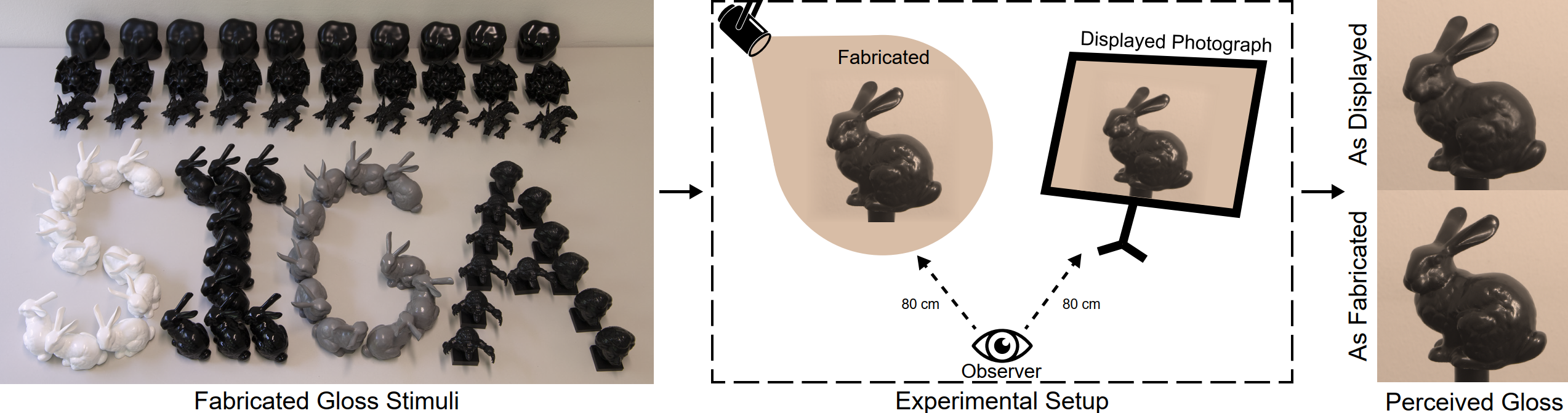
Abstract: A good match of material appearance between real-world objects and their digital on-screen representations is critical for many applications such as fabrication, design, and e-commerce. However, faithful appearance reproduction is challenging, especially for complex phenomena, such as gloss. In most cases, the view-dependent nature of gloss and the range of luminance values required for reproducing glossy materials exceeds the current capabilities of display devices. As a result, appearance reproduction poses significant problems even with accurately rendered images. This paper studies the gap between the gloss perceived from real-world objects and their digital counterparts. Based on our psychophysical experiments on a wide range of 3D printed samples and their corresponding photographs, we derive insights on the influence of geometry, illumination, and the display's brightness and measure the change in gloss appearance due to the display limitations. Our evaluation experiments demonstrate that using the prediction to correct material parameters in a rendering system improves the match of gloss appearance between real objects and their visualization on a display device.
Learning a self-supervised tone mapping operator via feature contrast masking loss
Chao Wang, Bin Chen, Hans-Peter Seidel, Karol Myszkowski, and Ana Serrano
Computer Graphics Forum (Eurographics 2022)

Abstract: High Dynamic Range (HDR) content is becoming ubiquitous due to the rapid development of capture technologies. Neverthe-less, the dynamic range of common display devices is still limited, therefore tone mapping (TM) remains a key challenge forimage visualization. Recent work has demonstrated that neural networks can achieve remarkable performance in this task whencompared to traditional methods, however, the quality of the results of these learning-based methods is limited by the train-ing data. Most existing works use as training set a curated selection of best-performing results from existing traditional tonemapping operators (often guided by a quality metric), therefore, the quality of newly generated results is fundamentally limitedby the performance of such operators. This quality might be even further limited by the pool of HDR content that is used fortraining. In this work we propose a learning-based self-supervised tone mapping operator that is trained at test time specificallyfor each HDR image and does not need any data labeling. The key novelty of our approach is a carefully designed loss functionbuilt upon fundamental knowledge on contrast perception that allows for directly comparing the content in the HDR and tonemapped images. We achieve this goal by reformulating classic VGG feature maps into feature contrast maps that normalizelocal feature differences by their average magnitude in a local neighborhood, allowing our loss to account for contrast maskingeffects. We perform extensive ablation studies and exploration of parameters and demonstrate that our solution outperformsexisting approaches with a single set of fixed parameters, as confirmed by both objective and subjective metrics.
Modeling Surround-aware Contrast Sensitivity
Shinyoung Yi, Daniel S. Jeon, Ana Serrano, Se-Yoon Jeong, Hui-Yong Kim, Diego Gutierrez, Min H. Kim
Computer Graphics Forum (EGSR), 2022

Abstract: Despite advances in display technology, many existing applications rely on psychophysical datasets of human perception gathered using older, sometimes outdated displays. As a result, there exists the underlying assumption that such measurements can be carried over to the new viewing conditions of more modern technology. We have conducted a series of psychophysical experiments to explore contrast sensitivity using a state-of-the-art HDR display, taking into account not only the spatial frequency and luminance of the stimuli but also their surrounding luminance levels. From our data, we have derived a novel surroundaware contrast sensitivity function (CSF), which predicts human contrast sensitivity more accurately. We additionally provide a practical version that retains the benefits of our full model, while enabling easy backward compatibility and consistently producing good results across many existing applications that make use of CSF models. We show examples of effective HDR video compression using a transfer function derived from our CSF, tone-mapping, and improved accuracy in visual difference prediction.
A Generative Framework for Image-based Editing of Material Appearance using Perceptual Attributes
Johanna Delanoy, Manuel Lagunas, Jorge Condor, Diego Gutierrez, Belen Masia
Computer Graphics Forum, 2022

Abstract: Single-image appearance editing is a challenging task, traditionally requiring the estimation of additional scene properties such as geometry or illumination. Moreover, the exact interaction of light, shape and material reflectance that elicits a given perceptual impression is still not well understood. We present an image-based editing method that allows to modify the material appearance of an object by increasing or decreasing high-level perceptual attributes, using a single image as input. Our framework relies on a two-step generative network, where the first step drives the change in appearance and the second produces an image with high-frequency details. For training, we augment an existing material appearance dataset with perceptual judgements of high-level attributes, collected through crowd-sourced experiments, and build upon training strategies that circumvent the cumbersome need for original-edited image pairs. We demonstrate the editing capabilities of our framework on a variety of inputs, both synthetic and real, using two common perceptual attributes (Glossy and Metallic), and validate the perception of appearance in our edited images through a user study.
On the Influence of Dynamic Illumination in the Perception of Translucency
Dario Lanza, Adrian Jarabo, Belen Masia
Symposium on Applied Perception (SAP), 2022
Abstract: Translucent materials are ubiquitous in the real world, from organic materials such as food or human skin, to synthetic materials like plastic or rubber. While multiple models for translucent materials exist, understanding how we perceive translucent appearance, and how it is affected by illumination and geometry, remains an open problem. In this work, we analyze how well human observers esti- mate the density of translucent objects for static and dynamic illu- mination scenarios. Interestingly, our results suggest that dynamic illumination may not be critical to assess the nature of translucent materials.
The effect of shape and illumination on material perception: model and applications
Ana Serrano, Bin Chen, Chao Wang, Michal Piovarci, Hans-Peter Seidel, Piotr Didyk, Karol Myszkowski
ACM Transactions on Graphics, Vol. 40(4) (SIGGRAPH 2021)

Abstract: Material appearance hinges on material reflectance properties but also surface geometry and illumination. The unlimited number of potential combinations between these factors makes understanding and predicting material appearance a very challenging task. In this work, we collect a large-scale dataset of perceptual ratings of appearance attributes with more than 215,680 responses for 42,120 distinct combinations of material, shape, and illumination. The goal of this dataset is twofold. First, we analyze for the first time the effects of illumination and geometry in material perception across such a large collection of varied appearances. We connect our findings to those of the literature, discussing how previous knowledge generalizes across very diverse materials, shapes, and illuminations. Second, we use the collected dataset to train a deep learning architecture for predicting perceptual attributes that correlate with human judgments. We demonstrate the consistent and robust behavior of our predictor in various challenging scenarios, which, for the first time, enables estimating perceived material attributes from general 2D images. Since our predictor relies on the final appearance in an image, it can compare appearance properties across different geometries and illumination conditions. Finally, we demonstrate several applications that use our predictor, including appearance reproduction using 3D printing, BRDF editing by integrating our predictor in a differentiable renderer, illumination design, or material recommendations for scene design
Single-image Full-body Human Relighting
Manuel Lagunas, Xin Sun, Jimei Yang, Ruben Villegas, Jianming Zhang, Zhixin Shu, Belen Masia, Diego Gutierrez
Eurographics Symposium on Rendering (EGSR), 2021

Abstract: We present a single-image data-driven method to automatically relight images with full-body humans in them. Our framework is based on a realistic scene leveraging precomputed radiance transfer (PRT) and spherical harmonics (SH) lighting. In contrast to previous work, we lift the assumptions on Lambertian materials and explicitly model diffuse and specular reflectance in our data. Moreover, we introduce an additional light-dependent residual term that accounts for errors in the PRTbased image reconstruction. We propose a new deep learning architecture, tailored to the decomposition performed in PRT, that is trained using a of L1, logarithmic, and rendering losses. Our model outperforms the state of the art for full-body human relighting both with synthetic images and photographs.
Perception of material appearance: a comparison between painted and rendered images
Johanna Delanoy, Ana Serrano, Belen Masia, Diego Gutierrez
Journal of Vision (JoV 2021), Vol.21, 5
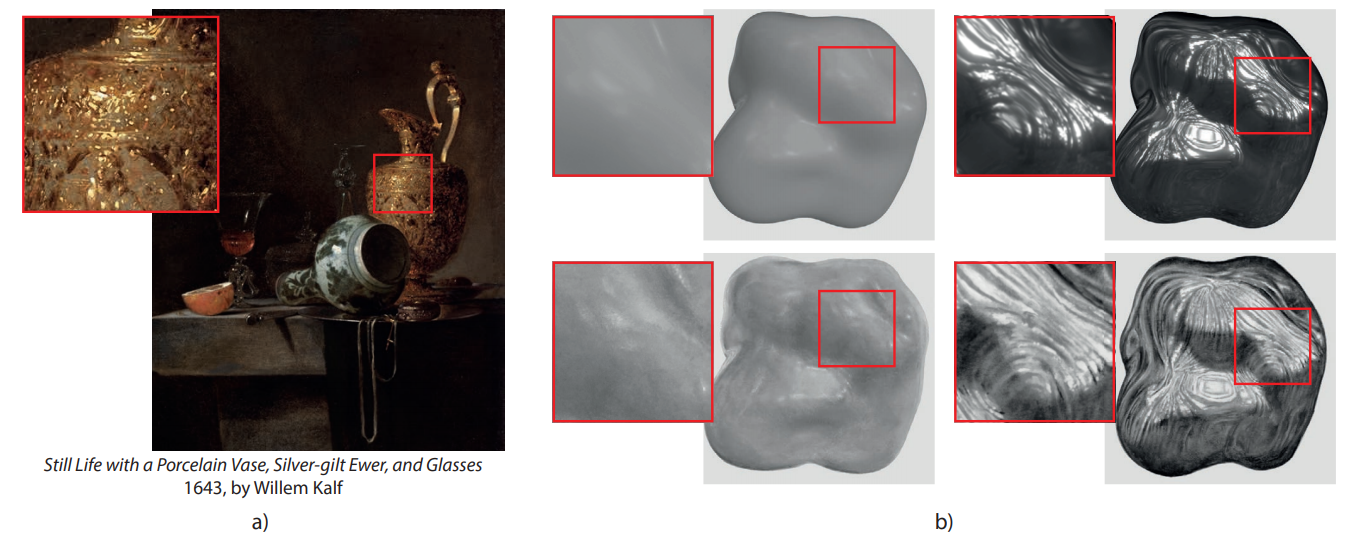
Abstract: Painters are masters in replicating the visual appearance of materials. While the perception of material appearance is not yet fully understood, painters seem to have acquired an implicit understanding of the key visual cues that we need to accurately perceive material properties. In this study, we directly compare the perception of material properties in paintings and in renderings, by collecting professional realistic paintings of rendered materials. From both type of images, we collect human judgments of material properties and compute a variety of image features that are known to reflect material properties. Our study reveals that, despite important visual differences between the two types of depiction, material properties in paintings and renderings are perceived very similarly and are linked to the same image features. This suggests that we use similar visual cues independently of the medium and that the presence of such cues is sufficient to provide a good appearance perception of the materials
The joint role of geometry and illumination on material recognition
Manuel Lagunas, Ana Serrano, Diego Gutierrez, Belen Masia
Journal of Vision (JoV 2021), Vol.21, 2
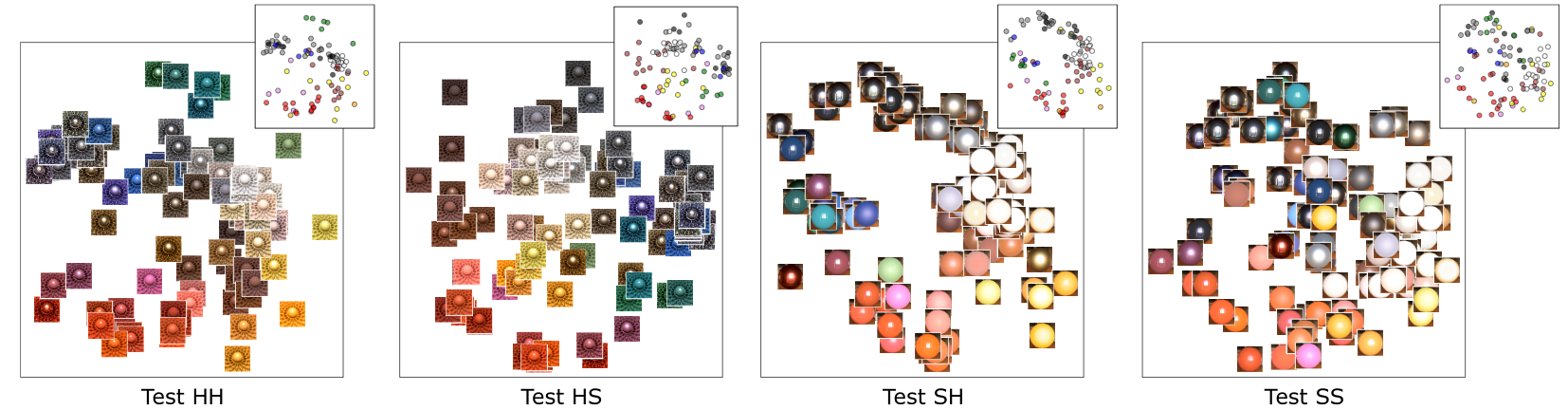
Abstract: Observing and recognizing materials is a fundamental part of our daily life. Under typical viewing conditions, we are capable of effortlessly identifying the objects that surround us and recognizing the materials they are made of. Nevertheless, understanding the underlying perceptual processes that take place to accurately discern the visual properties of an object is a long-standing problem. In this work, we perform a comprehensive and systematic analysis of how the interplay of geometry, illumination, and their spatial frequencies affect human performance on material recognition tasks. We carry out large-scale behavioral experiments where participants are asked to recognize different reference materials among a pool of candidate samples. In the different experiments, we carefully sample the information in the frequency domain of the stimuli. From our analysis, we find significant first-order interactions between the geometry and the illumination, of both the reference and the candidates. In addition, we observe that simple image statistics and higher-order image histograms do not correlate with human performance, therefore, we perform a high-level comparison of highly non-linear statistics by training a deep neural network on material recognition tasks. Our results show that such models can accurately classify materials, which suggests that they are capable of defining a meaningful representation of material appearance from labeled proximal image data. Last, we find preliminary evidence that these highly non-linear models and humans may use similar high-level factors for material recognition tasks.
The role of objective and subjective measures in material similarity learning
Johanna Delanoy, Manuel Lagunas, Ignacio Galve, Diego Gutierrez, Ana Serrano, Roland Fleming, Belen Masia
SIGGRAPH 2020 Poster
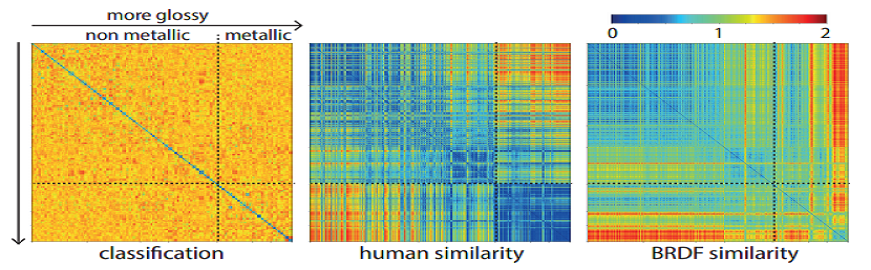
Abstract: Establishing a robust measure for material similarity that correlates well with human perception is a long-standing problem. A recent work presented a deep learning model trained to produce a feature space that aligns with human perception by gathering human subjective measures. The resulting metric outperforms objective existing ones. In this work, we aim to understand whether this increased performance is a result of using human perceptual data or is due to the nature of feature learnt by deep learning models. We train similar networks with objective measures (BRDF similarity or classification task) and show that these networks can predict human judgements as well, suggesting that the non-linear features learnt by convolutional network might be a key to model material perception.
A Similarity Measure for Material Appearance
Manuel Lagunas, Sandra Malpica, Ana Serrano, Elena Garces, Diego Gutierrez, Belen Masia
ACM Transactions on Graphics, Vol. 38(4) (SIGGRAPH 2019)

Abstract: We present a model to measure the similarity in appearance between different materials, which correlates with human similarity judgments. We first create a database of 9,000 rendered images depicting objects with varying materials, shape and illumination. We then gather data on perceived similarity from crowdsourced experiments; our analysis of over 114,840 answers suggests that indeed a shared perception of appearance similarity exists. We feed this data to a deep learning architecture with a novel loss function, which learns a feature space for materials that correlates with such perceived appearance similarity. Our evaluation shows that our model outperforms existing metrics. Last, we demonstrate several applications enabled by our metric, including appearance-based search for material suggestions, database visualization, clustering and summarization, and gamut mapping.
The Effect of Motion on the Perception of Material Appearance
Ruiquan Mao, Manuel Lagunas, Belén Masiá, Diego Gutierrez
ACM Symposium on Applied Perception (SAP '19), 2019
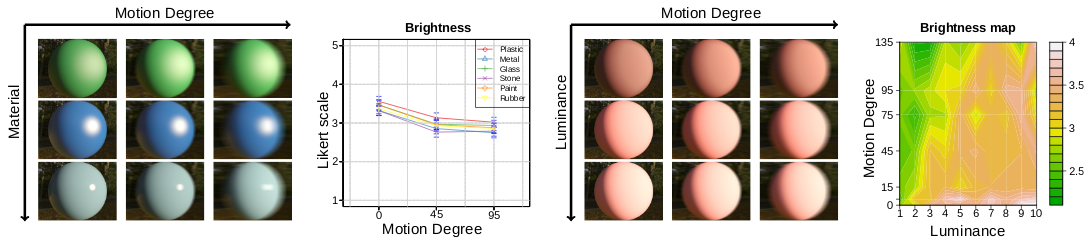
Abstract: We analyze the effect of motion in the perception of material appearance. First, we create a set of stimuli containing 72 realistic materials, rendered with varying degrees of linear motion blur. Then we launch a large-scale study on Mechanical Turk to rate a given set of perceptual attributes, such as brightness, roughness, or the perceived strength of reflections. Our statistical analysis shows that certain attributes undergo a significant change, varying appearance perception under motion. In addition, we further investigate the perception of brightness, for the particular cases of rubber and plastic materials. We create new stimuli, with ten different luminance levels and seven motion degrees. We launch a new user study to retrieve their perceived brightness. From the users’ judgements, we build two-dimensional maps showing how perceived brightness varies as a function of the luminance and motion of the material.
An Appearance Model for Textile Fibers
Carlos Aliaga, Carlos Castillo, Diego Gutierrez, Miguel A. Otaduy, Jorge Lopez-Moreno, Adrian Jarabo
Computer Graphics Forum, Vol. 36(4) (EGSR 2017)

Abstract: Accurately modeling how light interacts with cloth is challenging, due to the volumetric nature of cloth appearance and its multiscale structure, where microstructures play a major role in the overall appearance at higher scales. Recently, significant effort has been put on developing better microscopic models for cloth structure, which have allowed rendering fabrics with unprecedented fidelity. However, these highly-detailed representations still make severe simplifications on the scattering by individual fibers forming the cloth, ignoring the impact of fibers' shape, and avoiding to establish connections between the fibers' appearance and their optical and fabrication parameters. In this work we put our focus in the scattering of individual cloth fibers; we introduce a physically-based scattering model for fibers based on their low-level optical and geometric properties, relying on the extensive textile literature for accurate data. We demonstrate that scattering from cloth fibers exhibits much more complexity than current fiber models, showing important differences between cloth type, even in averaged conditions due to longer views. Our model can be plugged in any framework for cloth rendering, matches scattering measurements from real yarns, and is based on actual parameters used in the textile industry, allowing predictive bottom-up definition of cloth appearance.
Attribute-preserving gamut mapping of measured BRDFs
Tiancheng Sun, Ana Serrano, Diego Gutierrez, Belen Masia
SIGGRAPH 2017 Poster
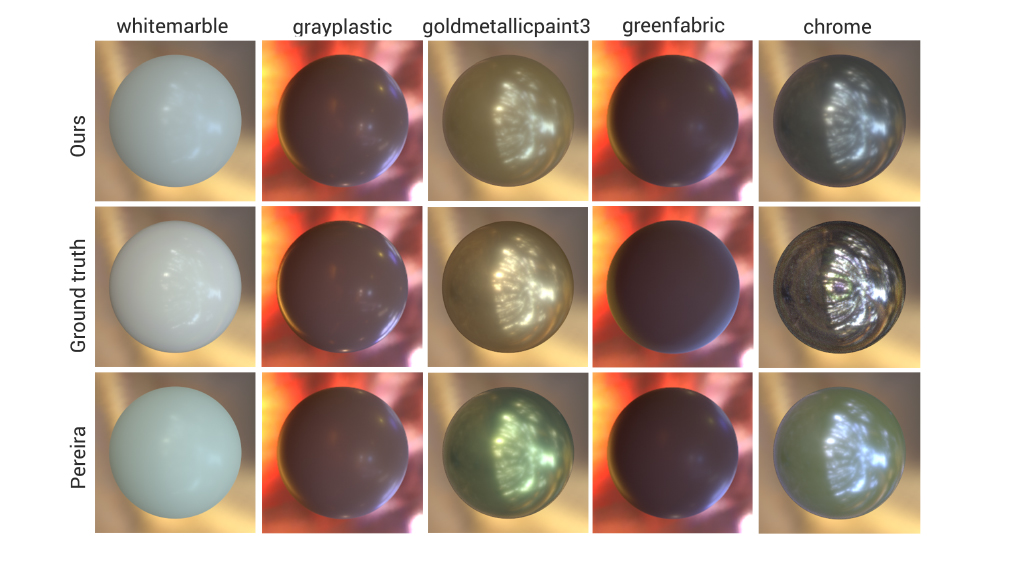
Abstract: Reproducing the appearance of real-world materials using current printing technology is problematic. The reduced number of inks available define the printer’s limited gamut, creating distortions in the printed appearance that are hard to control. Gamut mapping refers to the process of bringing an out-of-gamut material appearance into the printer’s gamut, while minimizing such distortions as much as possible. We present a novel two-step gamut mapping algorithm that allows users to specify which perceptual attribute of the original material they want to preserve (such as brightness, or roughness). In the first step, we work in the low-dimensional intuitive appearance space recently proposed by Serrano et al., and adjust achromatic reflectance via an objective function that strives to preserve certain attributes. From such intermediate representation, we then perform an image-based optimization including color information, to bring the BRDF into gamut. We show, both objectively and through a user study, how our method yields superior results compared to the state of the art, with the additional advantage that the user can specify which visual attributes need to be preserved. Moreover, we show how this approach can also be used for attribute-preserving material editing.
Improved Intuitive Appearance Editing based on Soft PCA
Sandra Malpica, Miguel Barrio, Diego Gutierrez, Ana Serrano, and Belen Masia
Spanish Computer Graphics Conference (CEIG), 2017

Abstract: During the last few years, many different techniques for measuring material appearance have arisen. These advances have allowed the creation of large public datasets, and new methods for editing BRDFs of captured appearance have been proposed. However, these methods lack intuitiveness and are hard to use for novice users. In order to overcome these limitations, Serrano et al. recently proposed an intuitive space for editing captured appearance. They make use of a representation of the BRDF based on a combination of principal components (PCA) to reduce dimensionality, and then map these components to perceptual attributes. This PCA representation is biased towards specular materials and fails to represent very diffuse BRDFs, therefore producing unpleasant artifacts when editing. In this paper, we build on top of their work and propose to use two separate PCA bases for representing specular and diffuse BRDFs, and map each of these bases to the perceptual attributes. This allows us to avoid artifacts when editing towards diffuse BRDFs. We then propose a new method for effectively navigate between both bases while editing based on a new measurement of the specularity of measured materials. Finally, we integrate our proposed method in an intuitive BRDF editing framework and show how some of the limitations of the previous model have been overcomed with our representation. Moreover, our new measure of specularity can be used on any measured BRDF, as it is not limited only to MERL BRDFs.
An Intuitive Control Space for Material Appearance
A. Serrano, D. Gutierrez, K. Myszkowski, H.P. Seidel, B. Masia
ACM Transactions on Graphics, Vol. 35(6) (SIGGRAPH Asia 2016)

Abstract: Many different techniques for measuring material appearance have been proposed in the last few years. These have produced large public datasets, which have been used for accurate, data-driven appearance modeling. However, although these datasets have allowed us to reach an unprecedented level of realism in visual appearance, editing the captured data remains a challenge. In this paper, we present an intuitive control space for predictable editing of captured BRDF data, which allows for artistic creation of plausible novel material appearances, bypassing the difficulty of acquiring novel samples. We first synthesize novel materials, extending the existing MERL dataset up to 400 mathematically valid BRDFs. We then design a large-scale experiment, gathering 56,000 subjective ratings on the high-level perceptual attributes that best describe our extended dataset of materials. Using these ratings, we build and train networks of radial basis functions to act as functionals mapping the perceptual attributes to an underlying PCA-based representation of BRDFs. We show that our functionals are excellent predictors of the perceived attributes of appearance. Our control space enables many applications, including intuitive material editing of a wide range of visual properties, guidance for gamut mapping, analysis of the correlation between perceptual attributes, or novel appearance similarity metrics. Moreover, our methodology can be used to derive functionals applicable to classic analytic BRDF representations. We release our code and dataset publicly, in order to support and encourage further research in this direction.