Abstract
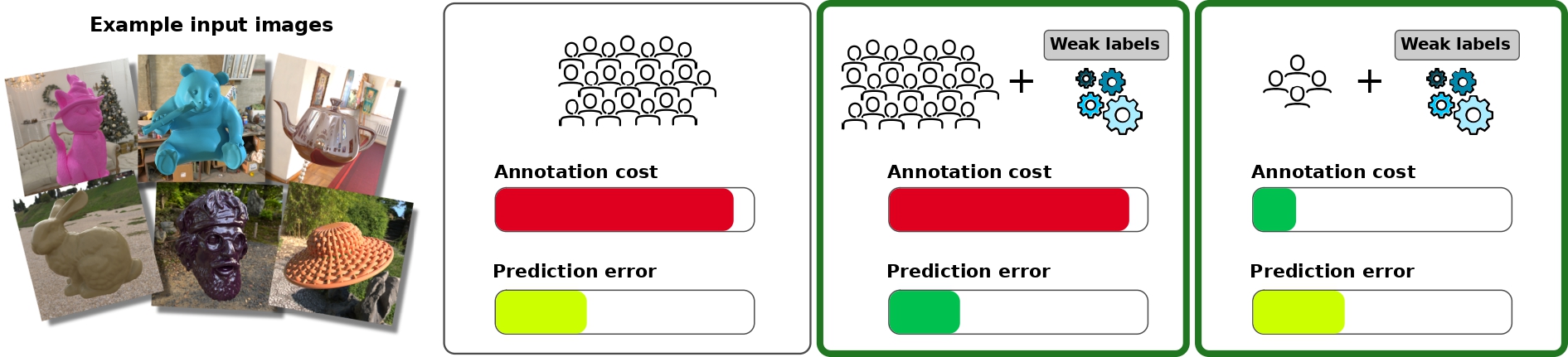
Estimating perceptual attributes of materials directly from images is a challenging task due to their complex, not fully-understood interactions with external factors, such as geometry and lighting. Supervised deep learning models have recently been shown to outperform traditional approaches, but rely on large datasets of human-annotated images for accurate perception predictions. Obtaining reliable annotations is a costly endeavor, aggravated by the limited ability of these models to generalise to different aspects of appearance. In this work, we show how a much smaller set of human annotations (strong labels) can be effectively augmented with automatically derived weak labels in the context of learning a low-dimensional image-computable gloss metric. We evaluate three alternative weak labels for predicting human gloss perception from limited annotated data. Incorporating weak labels enhances our gloss prediction beyond the current state of the art. Moreover, it enables a substantial reduction in human annotation costs without sacrificing accuracy, whether working with rendered images or real photographs.
Downloads
Bibtex
Acknowledgments
This work has received funding from the Spanish Agencia Estatal de Investigación (Project PID2022-141539NB-I00 funded by MCIN/AEI/10.13039/501100011033/FEDER, EU) and from the European Union’s Horizon 2020 research and innovation programme under the Marie Skłodowska-Curie grant agreement No. 956585 (PRIME). This research was also supported by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation—project number 222641018—SFB/TRR 135TP C1), by the European Research Council (ERC, Advanced Grant “STUFF”—project number ERC-2022-AdG-101098225), by the Marsden Fund of the Royal Society of New Zealand (MFPUOA2109) and by the Cluster Project “The Adaptive Mind”, funded by the Excellence Program of the Hessian Ministry of Higher Education, Science, Research and Art. Julia Guerrero-Viu was supported by the FPU20/02340 predoctoral grant and J. Daniel Subias was supported by the CUS/702/2022 predoctoral grant. We also thank Daniel Martin for helping with figures and the members of the Graphics and Imaging Lab for insightful discussions.