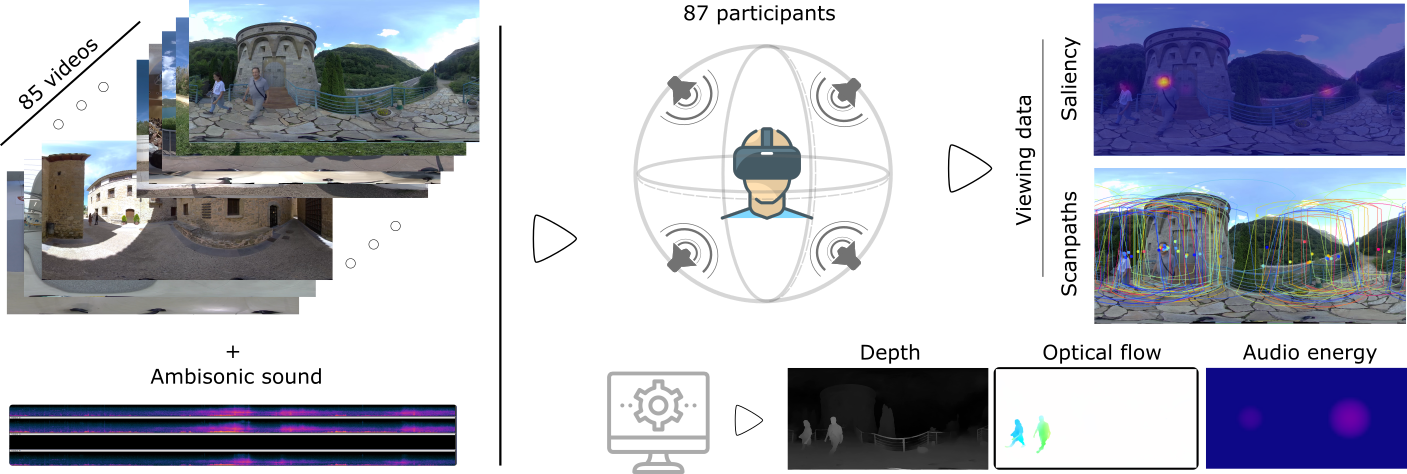
Understanding human visual behavior within virtual reality environments is crucial to fully leverage their potential. While
previous research has provided rich visual data from human observers, existing gaze datasets often suffer from the absence of
multimodal stimuli. Moreover, no dataset has yet gathered eye gaze trajectories (i.e., scanpaths) for dynamic content with directional
ambisonic sound, which is a critical aspect of sound perception by humans. To address this gap, we introduce D-SAV360, a dataset
of 4,609 head and eye scanpaths for 360º videos with first-order ambisonics. This dataset enables a more comprehensive study of
multimodal interaction on visual behavior in VR environments. We analyze our collected scanpaths from a total of 87 participants
viewing 85 different videos and show that various factors such as viewing mode, content type, and gender significantly impact eye
movement statistics. We demonstrate the potential of D-SAV360 as a benchmarking resource for state-of-the-art attention prediction
models and discuss its possible applications in further research. By providing a comprehensive dataset of eye movement data for
dynamic, multimodal virtual environments, our work can facilitate future investigations of visual behavior and attention in virtual reality.
D-SAV360 is composed of 50 stereoscopic and 35 monoscopic videos with ambisonic sounds. We provide the collected gaze data from 87 participants,
the computed saliency maps, the estimated optical flow (obtained using RAFT), the estimated depth, and the computed Audio Energy Maps.
Additionally, we provide our capture and visualization system for Unity, which can be used to capture new gaze data.
The dataset and documentation is available for download in the following links:
A taxonomy for our dataset D-SAV360. Our taxonomy provides a structured classification that facilitates a more comprehensive analysis for future research on visual behavior in virtual reality.
@article{Bernal-Berdun2023dsav360,
author={Bernal-Berdun, Edurne and Martin, Daniel and Malpica, Sandra and Perez, Pedro J. and Gutierrez, Diego and Masia, Belen and Serrano, Ana},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={D-SAV360: A Dataset of Gaze Scanpaths on $360^{\circ}$ Ambisonic Videos},
year={2023},
volume={},
number={},
pages={1-11},
doi={10.1109/TVCG.2023.3320237}}
- 2022: SST-Sal: A spherical spatio-temporal approach for saliency prediction in 360º videos
@article{BERNAL-BERDUN2022,
title = {SST-Sal: A spherical spatio-temporal approach for saliency prediction in 360∘ videos},
journal = {Computers & Graphics},
year = {2022},
issn = {0097-8493},
doi = {https://doi.org/10.1016/j.cag.2022.06.002},
url = {https://www.sciencedirect.com/science/article/pii/S0097849322001042},
author = {Edurne Bernal-Berdun and Daniel Martin and Diego Gutierrez and Belen Masia},
keywords = {Virtual reality, Scene Understanding, Saliency},
abstract = {Virtual reality (VR) has the potential to change the way people consume content, and has been predicted to become the next big computing paradigm. However, much remains unknown about the grammar and visual language of this new medium, and understanding and predicting how humans behave in virtual environments remains an open problem. In this work, we propose a novel saliency prediction model which exploits the joint potential of spherical convolutions and recurrent neural networks to extract and model the inherent spatio-temporal features from 360° videos. We employ Convolutional Long Short-Term Memory cells (ConvLSTMs) to account for temporal information at the time of feature extraction rather than to post-process spatial features as in previous works. To facilitate spatio-temporal learning, we provide the network with an estimation of the optical flow between 360° frames, since motion is known to be a highly salient feature in dynamic content. Our model is trained with a novel spherical Kullback–Leibler Divergence (KLDiv) loss function specifically tailored for saliency prediction in 360° content. Our approach outperforms previous state-of-the-art works, being able to mimic human visual attention when exploring dynamic 360° videos.}
}
- 2022: ScanGAN360: A Generative Model of Realistic Scanpaths for 360º Images
@article{martin2022scangan360,
title={ScanGAN360: A Generative Model of Realistic Scanpaths for 360° Images},
author={Martin, Daniel and Serrano, Ana and Bergman, Alexander W and Wetzstein, Gordon and Masia, Belen},
journal={IEEE Transactions on Visualization and Computer Graphics},
volume={28},
number={5},
pages={2003--2013},
year={2022},
publisher={IEEE}
}
- 2020: Panoramic convolutions for 360º single-image saliency prediction
@inproceedings{martin20saliency,
author={Martin, Daniel and Serrano, Ana and Masia, Belen},
title={Panoramic convolutions for $360^{\circ}$ single-image saliency prediction},
booktitle={CVPR Workshop on Computer Vision for Augmented and Virtual Reality},
year={2020}
}